Minu Google Colab märkmik aga parem vaata fastai 04_mnist_basic.
Üks tuntumaid andmestike (dataset) on MNIST, mis sisaldab käsitsikirjutatud numbreid. Seda kasutati ühes esimeses praktilises käsitsikirjutatud numbrijärjestuste äratundmise süsteemis Lenet-5 aastal 1998.
Laemealla MNIST_SAMPLE andmestiku. See sisaldab ainult numbreid 3 ja 7!
path = untar_data(URLs.MNIST_SAMPLE)
Path.BASE_PATH = pathKuvame selle kataloogi (path) sisu:
path.ls()Masinõppe andmestikud (datasets) on tavaliselt jaotatud eraldi kataloogideks: treeningandmestik (training set) ja valideerimisandmestik (validation set).
Vaatame, mis on treeningandmestikus:
(path/'train').ls()Näeme, et on eraldi kataloogid 3 ja 7. Need on märgendid (labels) (või eesmärgid (targets)) selles andmestikus.
Vaatame veel sügavamale:
threes = (path/'train'/'3').ls().sorted()
sevens = (path/'train'/'7').ls().sorted()
threesNäeme, et need kataloogid sisaldavad pilte numbritest.
Kuvame ühe neist piltidest:
im3_path = threes[5]
im3 = Image.open(im3_path)
im3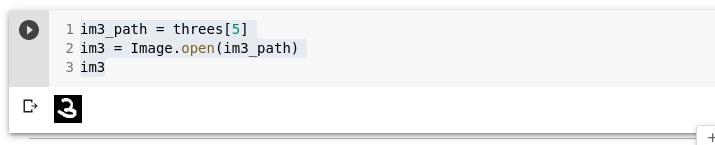
Arvutis on kõik esindatud numbritena. Et näha numbreid (piksleid) millest see pilt koosneb peame selle muutma Numpy array-ks või PyTorch tensor-iks.
NumPy array näeb välja selline:
array(im3)[4:10,4:10]4:10 tähendab, et näitab ridu 4 kuni 10 ja sama ka tulpade kohta. Kuni 10 tähendab, et kuvab kohani kohani kust hakkab rida 10 st viimane rida mida näeme on 9.
PyTorch tensor näeb välja selline:
tensor(im3)[4:10,4:10]Saame kuvada veel täpsemini pilti ja pikslite väärtusi:
im3_t = tensor(im3)
df = pd.DataFrame(im3_t[4:15,4:22])
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')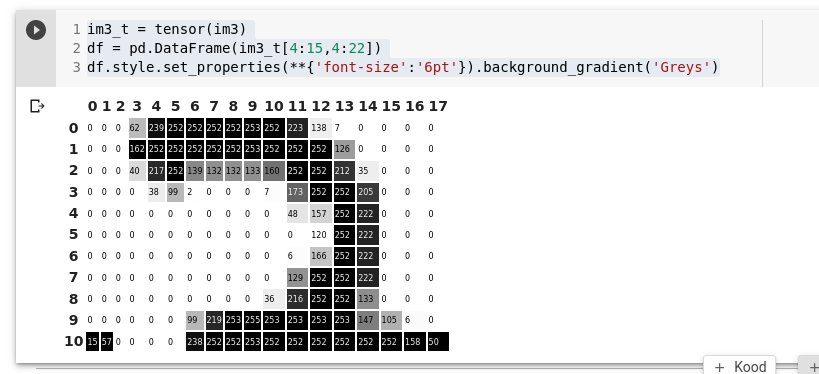
Andmestik koosneb piltidest 28*28 pikslit. Kokku 784px üks pilt.
Meetod 1: Pikslite sarnasus
Keskmine pikslite väärtus igas gruppis.
Loome tensori, mis sisaldab kõiki kolmede ja seitsmete pilte. Kasutades selleks list comprehension. Selle tulemusena saame listi, kus on kõik pildid.
new_list = [f(o) for o in a_list if o>0]
Tagastab iga elemendi listist a_list, mis on suurem, kui 0. Lastes selle enne läbi funtsioonist f(o). if o>0 on valikuline filter.
new_list = [f(o) for o in a_list]
seven_tensors = [tensor(Image.open(o)) for o in sevens]
three_tensors = [tensor(Image.open(o)) for o in threes]
len(three_tensors),len(seven_tensors)Kontrollime, kuvades ühe pildi tensorist:
show_image(three_tensors[1]);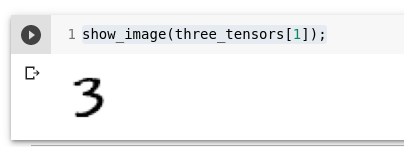
Kombineerime kõik pildi kokku üheks kolme dimensiooniliseks tensoriks. Seda kutsutakse rank-3 tensor. Kasutame selleks PyTorch funktsiooni stack.
Kuna hiljem on vaja arvutada keskmiseid (mean) peame muutma väärtused ujukomaarvudeks (float).
Kui pildid on esitatud ujukomaarvudena (float) on pikslite väärtused 0 ja 1 vahel. Selleks jagame piksli väärtuse 255.
stacked_sevens = torch.stack(seven_tensors).float()/255
stacked_threes = torch.stack(three_tensors).float()/255
stacked_threes.shapeshape – on tensori dimensioonide mõõtmed. 6161 sügavus (pilti), laius-kõrgus on 28×28.
rank – on tensori dimensioonide arv rank = len(stacked_threes.shape) või rank = stacked_threes.ndim
len(stacked_threes.shape) # Esimene võimalus
stacked_threes.ndim # Teine võimalusArvutame nüüd keskmise (mean) pikslite väärtuse iga numbri puhul. Saame ideaalse kolme, mis esindab kõiki kolmesid.
mean3 = stacked_threes.mean(0)
show_image(mean3);mean7 = stacked_sevens.mean(0)
show_image(mean7);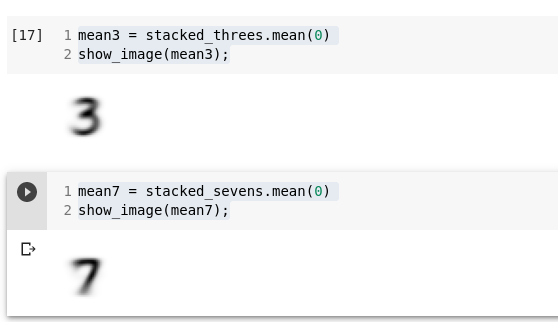
Number on must seal, kus kõik pildid nõustuvad, et peaks olema must ja udusem ja heledam seal, kus erinevad pildid on erineval arvamusel.
a_3 = stacked_threes[1]
show_image(a_3);
Et mõõta, kui sarnased (lähedal) või erinevad (kaugel) pildid on, on kaks võimalust:
- Kahe pildi erinevuste absoluutväärtuste keskmised. mean absolute difference or L1 norm
- Erinevuste ruudu (teem kõik positiivseks) keskmine ja seejärel ruutjuur. Root mean squared error (RMSE) or L2 norm
dist_3_abs = (a_3 - mean3).abs().mean()
dist_3_sqr = ((a_3 - mean3)**2).mean().sqrt()
dist_3_abs,dist_3_sqrdist_7_abs = (a_3 - mean7).abs().mean()
dist_7_sqr = ((a_3 - mean7)**2).mean().sqrt()
dist_7_abs,dist_7_sqrMõlemal juhul on distants meie 3 ja ideaalse 3 vahel väiksem, kui distants ideaalse 7ni. Seega meie lihtne mudel annab õige vastuse.
PyTorch pakub juba mõlemat neist juba kahjufunktsioonina (loss functions).
Need on juba imporditud fastai’ga. Aga muul juhul import torch.nn.functional as F
F.l1_loss(a_3.float(),mean7), F.mse_loss(a_3,mean7).sqrt()mse – mean squared error
l1 – mean absolute value (in math it’s called the L1 norm).
L1 loss is just equal to (a-b).abs().mean(), where a and b are tensors.
NumPy array ja PyTorch tensorid
NumPy on kõige levinum teek teaduslike arvutuste jaoks. NumPy arrayd ja PyTorch tsensorid on väga sarnased aga NumPy ei toeta GPU kasutamist, mis on sügavõppes väga levinud.
Python ise on väga aegalane võrreldes kompileeritavate keeltega (c/c++, rust jne). Kõik kiired osad Pythonis, NumPy või PyTorchis on tegelikul kirjutatud C-keels ja neil on Pythoni liides, et oleks lihtne kasutada.
NumPy array on mitmedimensiooniline ühetüübiliste andmete tabel.
Array ja tensori loomine:
data = [[1,2,3],[4,5,6]]
arr = array (data) # numpy
tns = tensor(data) # pytorch
# Kuvame
arr
tnsRea valimine:
tns[1] # Lugemine 0istTulba valimine:
tns[:,1]Mingi osa valimine:
tns[1,1:3]Kasutada operaatoreid +, -, *, /:
tns+1Tensoril on tüüp:
tns.type()Muudab automaatselt tsensori tüüpi.
tns*1.5 # into to floatMõõdik (Metric)
Loome tensori valideerimisandmestikust
valid_3_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'3').ls()])
valid_3_tens = valid_3_tens.float()/255
valid_7_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'7').ls()])
valid_7_tens = valid_7_tens.float()/255
valid_3_tens.shape,valid_7_tens.shape # Kontrollime tensori kujuLihtne funktsioon, mis arvutav kahe pildi kauguse (erinevuse):
mean3 on meie ideaalne 3 a_3 on suvaline 3
def mnist_distance(a,b):
# abs - absolute values
# -1 viimane elememt, -2 eelviimane element
return (a-b).abs().mean((-1,-2)) # valime 2 viimast Dimensiooni laius/kõrgus
mnist_distance(a_3, mean3)Kui tahame korraga arvuta kõigi valideerimisanmestikus olevate pilti kaugust saame terve tensori korraga lasta funktsioonist läbi: broadcasting !
valid_3_dist = mnist_distance(valid_3_tens, mean3) # broadcasting!
valid_3_dist, valid_3_dist.shapeKas on 3 või ei ole. Kui tundmatu pildi (x) kaugus ideaalsest 3 on väiksem, kui kaugus ideaalset 7 siis on ta 3.def is_3(x):
return mnist_distance(x,mean3) < mnist_distance(x,mean7)Katsetame. Kui muudame True ujukomaks saame 1.0 ja False 0.0
is_3(a_3), is_3(a_3).float() # True ja 1. (== True)is_3(valid_3_tens)Nüüd arvutame kõigi 3 ja 7 täpsuse
accuracy_3s = is_3(valid_3_tens).float() .mean()
accuracy_7s = (1 - is_3(valid_7_tens).float()).mean()
accuracy_3s,accuracy_7s,(accuracy_3s+accuracy_7s)/2Meetod 2. Stochastic Gradient Descent (SGD)
Sügavõppe mudeli treenimise ettapid:
- Initsialiseeri kaalud (weights)
- Kasuta neid kaalusid, et ennustada (predict) kas pilt on 3 või 7.
- Ennustuste abil arvuta, kui hea mudel on (loss).
- Arvuta gradient, mis mõõdab iga kaalu kohta, kuidas selle kaalu muutus muudab mudeli headust (loss).
- Step Muuda kõiki kaalusid selle arvutuse põhjal.
- Tagasi punkti 2. ja korda.
- Korda niikaua, kui mudel on piisavalt hea.
Illustreerime lihtsa näidisega
Ütleme, et see on meie kaofunktsioon (loss function):
def f(x): return x**2plot_function(f, 'x', 'x**2')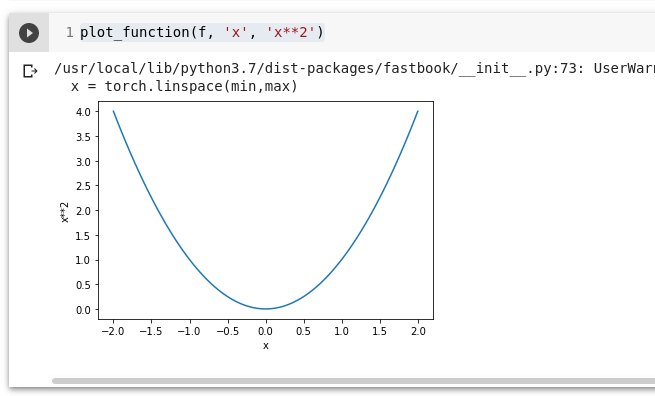
Valime juhusliku väärtuse kaalule (parameter) ja arvutame kao (loss).
plot_function(f, 'x', 'x**2')
plt.scatter(-1.5, f(-1.5), color='red');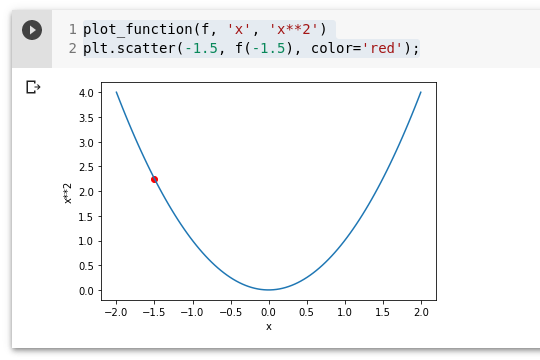
Nüüd vaatame, mis juhtub, kui suurendame või vähendame natuke kaalu.
Gradient’i arvutamine
Valime tensori väärtuse mille gradienti soovime:
xt = tensor(3.).requires_grad_()Arvutame funktisooni:
yt = f(xt)
ytArvutame gradiendi:
yt.backward()backward – backpropagation
Vaatame gradienti:
xt.gradxt = tensor([3.,4.,10.]).requires_grad_()
xtKordame vektor argumendiga
xt = tensor([3.,4.,10.]).requires_grad_()
xtLisame funktsiooni summa, et saaks võtta vektori (rnk-1 tensor) ja tagasta skaalari (rank-0 tensor):
def f(x): return (x**2).sum()
yt = f(xt)
ytMeie gradient on 2*xt
yt.backward()
xt.gradGradiendid ütlevad meile ainult funktsiooni kallaku. Kui kallak on väga suur on meil vaja teha rohkem kohandusi. Kui väike, väike võib see tähendada, et oleme optimaalse lähedal.
Otsus, kuidas muuta parameetreid gradiendi põhjal on oluline osa õppimis protsessis. Peaaegu kõik lähenemised algavad põhiideest gradienti korrutamiseks mõne väikse arvuga, mida nimetetakse õpimääraks (LR learning rate) On tihti number 0.001 ja 0.1 vahel.
w -= gradient(w) * lr
This is known as stepping your parameters, using an optimizer step.
Kui valida liiga väike õppemäär (learning rate) võib see tähendada väga paljude sammude (steps) tegmist. Liiga suur õppemäär võib tähenda kao (loss) suurenemist.
SGD näide
time = torch.arange(0,20).float();
time
speed = torch.randn(20)*3 + 0.75*(time-9.5)**2 + 1
plt.scatter(time,speed);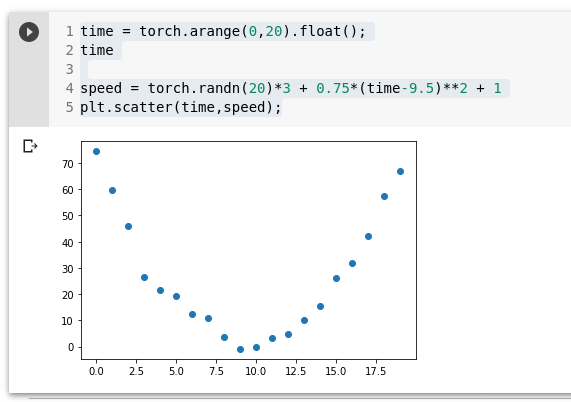
def f(t, params):
a,b,c = params
return a*(t**2) + (b*t) + cdef mse(preds, targets):
return ((preds-targets)**2).mean().sqrt()1. Parameetrite initsialiseerimine
Juhuslike väärtustega. Gradientide jälgimine
params = torch.randn(3).requires_grad_()
orig_params = params.clone()2. Ennustuse arvutamine
preds = f(time, params)Funktsioon kui lähedal, meie ennustused on:
def show_preds(preds, ax=None):
if ax is None: ax=plt.subplots()[1]
ax.scatter(time, speed)
ax.scatter(time, to_np(preds), color='red') # ennustused on punased
ax.set_ylim(-300,100)
show_preds(preds)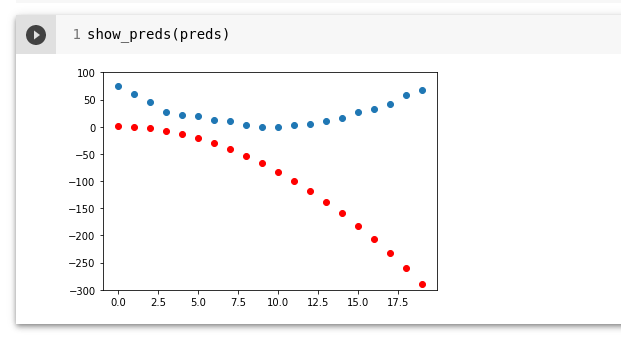
3. Kao arvutamine
loss = mse(preds, speed)
loss4. Gradiendi arvutamine
ehk arvutada parameetrite muutmise vajadus.
loss.backward()
params.grad
params.grad * 1e-5 # Learning rate = 0.00001
params5. Parameetrite ehk kaalude (weights) sammuvõrra suurendamine
lr = 1e-5
params.data -= lr * params.grad.data
params.grad = NoneVaatma kas kadu (loss) on paranenud:
preds = f(time,params)
mse(preds, speed)
show_preds(preds)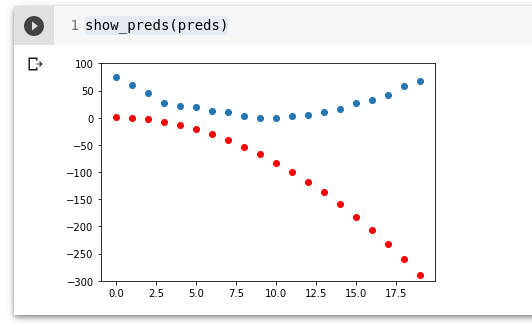
Peame kordama seda mitu korda. Et oleks lihtsam teeme funktsiooni:
def apply_step(params, prn=True):
preds = f(time, params)
loss = mse(preds, speed)
loss.backward()
params.data -= lr * params.grad.data
params.grad = None
if prn: print(loss.item())
return preds6. Korda
for i in range(10): apply_step(params)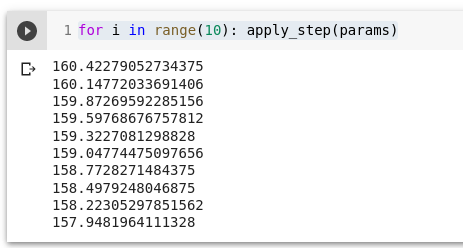
params = orig_params.detach().requires_grad_()Kadu (loss) väheneb.
_,axs = plt.subplots(1,4,figsize=(12,3))
for ax in axs:
show_preds(apply_step(params, False), ax)
plt.tight_layout()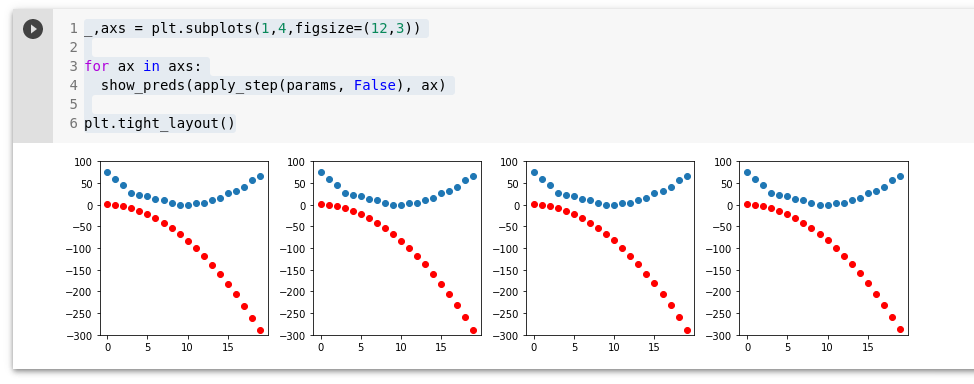
7. Stop
Pärast 10 epohhi oleme otsustanud lõpetada.
Kokkuvõte
Parameetrid (kaalud – weights) võivad algul on juhuslikud, kui treenime nullist. Või tulla eeltreenitud mudelist (transfer learning). Mõlemal juhul peab mudel õppima, et leida paremaid parameetreid (weights).
Võrdleme mudelite väljundeid eesmärgiga (targets) kasutades kaofuntktsiooni (loss), mis peab olema võimalikult väike. Meil on märgendatud andmed seega teame millised meie eesmärgid välja näevad.
Parameetrite muutmiseks arvutame gradiendi.
MNISTi kaofunktsioon (Loss Function)
Kõik pildid ühte tensorisse (independent variable) ja muudame nad maatriksite nimekirjast (list of matrices, a rank-3 tensor) vektorite nimekirjaks (list of vectors, a rank-2 tensor). Tähistame X-iga.
train_x = torch.cat([stacked_threes, stacked_sevens]).view(-1, 28*28)Märgitame kõik pildid. 1 tähistab kolme ja 0 tähistab seitset.
train_y = tensor([1]*len(threes) + [0]*len(sevens)).unsqueeze(1)
train_x.shape,train_y.shapeIndekseerimisel PyTorchis peab andemkogu tagastame tuple (x, y)
dset = list(zip(train_x,train_y))
x,y = dset[0]
x.shape,y
valid_x = torch.cat([valid_3_tens, valid_7_tens]).view(-1, 28*28)
valid_y = tensor([1]*len(valid_3_tens) + [0]*len(valid_7_tens)).unsqueeze(1)
valid_dset = list(zip(valid_x,valid_y))Initsialiseerimine
def init_params(size, std=1.0):
return (torch.randn(size)*std).requires_grad_()
weights = init_params((28*28,1))
bias = init_params(1)Kaalud (weight) ja kallutatus (bias) moodustavad kokku parameetri.
Ühe pildi ennustus:
(train_x[0]*weights.T).sum() + biasKorrutame maatriksid omavahel:
def linear1(xb):
return xb@weights + bias
preds = linear1(train_x)
predsKontrollime täpsust
corrects = (preds>0.5).float() == train_y
corrects
corrects.float().mean().item()
preds = linear1(train_x)
((preds>0.0).float() == train_y).float().mean().item()Kaofunktsioon
trgts = tensor([1,0,1])
prds = tensor([0.9, 0.4, 0.2])
def mnist_loss(predictions, targets):
return torch.where(targets==1, 1-predictions, predictions).mean()
torch.where(trgts==1, 1-prds, prds)
mnist_loss(prds,trgts)
mnist_loss(tensor([0.9, 0.4, 0.8]),trgts)Sigmoid
Sigmoidfunktsiooni väljund on alati 0 ja 1 vahel.
Näidis: (PuTorchil on oma seega pole tegelikult vaja)
def sigmoid(x):
return 1/(1+torch.exp(-x))
plot_function(torch.sigmoid, title='Sigmoid', min=-4, max=4)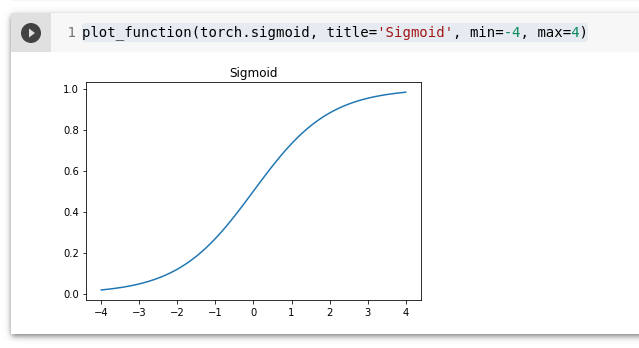
Uuendame mnist_loss funktsiooni
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()Initsialiseerime uuesti:
weights = init_params((28*28,1))
bias = init_params(1)Loome DataLoaderi andmestikust (dataset)
dl = DataLoader(dset, batch_size=256)
xb,yb = first(dl)
xb.shape,yb.shapeValideerimisandmekogu DataLoader
valid_dl = DataLoader(valid_dset, batch_size=256)Mini-batch suurusega 4
batch = train_x[:4]
batch.shape
preds = linear1(batch)
preds
loss = mnist_loss(preds, train_y[:4])
lossArvutame gradiendi
loss.backward()
weights.grad.shape,weights.grad.mean(),bias.gradPaneme selle kõik funktsiooni
def calc_grad(xb, yb, model):
preds = model(xb)
loss = mnist_loss(preds, yb)
loss.backward()testime seda
calc_grad(batch, train_y[:4], linear1)
weights.grad.mean(),bias.grad
# set the current gradients to 0 first:
weights.grad.zero_()
bias.grad.zero_();def train_epoch(model, lr, params):
for xb,yb in dl:
calc_grad(xb, yb, model)
for p in params:
p.data -= p.grad*lr
p.grad.zero_()
def batch_accuracy(xb, yb):
preds = xb.sigmoid()
correct = (preds>0.5) == yb
return correct.float().mean()
batch_accuracy(linear1(batch), train_y[:4])def validate_epoch(model):
accs = [batch_accuracy(model(xb), yb) for xb,yb in valid_dl]
return round(torch.stack(accs).mean().item(), 4)
validate_epoch(linear1)Treenime 1 epohhi
lr = 1.
params = weights,bias
train_epoch(linear1, lr, params)
validate_epoch(linear1)ja veel mõned korrad
for i in range(20):
train_epoch(linear1, lr, params)
print(validate_epoch(linear1), end=' ')Optimeerija loomine
Ssendame meie linera1 funktsiooni PyTorchi nn.Linear mooduliga. nn.Linear ühendab endas init_params ja linear.
linear_model = nn.Linear(28*28,1)
w,b = linear_model.parameters()
w.shape,b.shapeTeeme optimeerija
class BasicOptim:
def __init__(self,params,lr): self.params,self.lr = list(params),lr
def step(self, *args, **kwargs):
for p in self.params: p.data -= p.grad.data * self.lr
def zero_grad(self, *args, **kwargs):
for p in self.params: p.grad = None
opt = BasicOptim(linear_model.parameters(), lr)
def train_epoch(model):
for xb,yb in dl:
calc_grad(xb, yb, model)
opt.step()
opt.zero_grad()
# Valideerimine
validate_epoch(linear_model)
def train_model(model, epochs):
for i in range(epochs):
train_epoch(model)
print(validate_epoch(model), end=' ')
train_model(linear_model, 20)Fastai SGD class teeb sama, mis meie BasicOtim
linear_model = nn.Linear(28*28,1)
opt = SGD(linear_model.parameters(), lr)
train_model(linear_model, 20)fastai on ka Learner-fit mida saame kasutada train_model asemel
dls = DataLoaders(dl, valid_dl)
learn = Learner(dls, nn.Linear(28*28,1), opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)
learn.fit(10, lr=lr)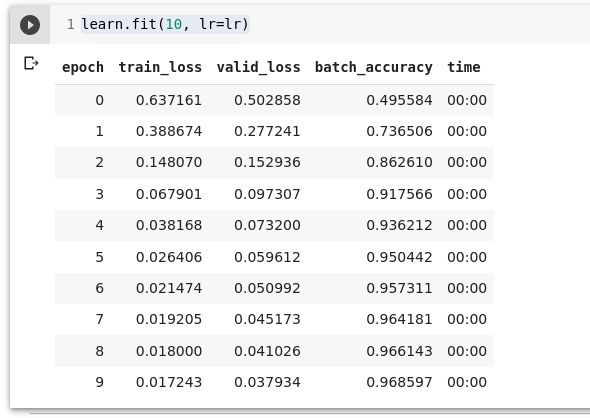
Mittelineaarsuse lisamine
Lihtne närvivõrk:
def simple_net(xb):
res = xb@w1 + b1
res = res.max(tensor(0.0))
res = res@w2 + b2
return res
w1 = init_params((28*28,30)) # weight tensor
b1 = init_params(30) # bias tensor
w2 = init_params((30,1))
b2 = init_params(1)w1’l on 30 väljundi aktiveerimist. st. w2’l peab olema 30 sisendi aktiveerimist.
Esimene kiht saab konstrueerida 30 erinevat omadust (feature), mis on kõik mingite pikslite segu. 30 asemel võib olla ükskõik mis teine number.
Funktsioon res.max(tensor(0.0)) on ReLU – rectified linear unit. PyTorch’is on see F.relu. Asendab iga negatiivse numbri nulligaga (0).
plot_function(F.relu)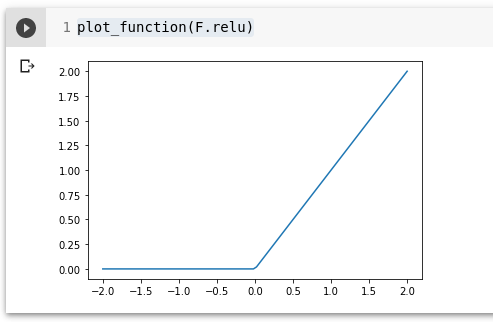
# module
simple_net = nn.Sequential(
nn.Linear(28*28,30), # Linear layer
nn.ReLU(), # Nonlinear layer - activation function
nn.Linear(30,1) # Linear layer
)
learn = Learner(dls, simple_net, opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)
learn.fit(40, 0.1)
plt.plot(L(learn.recorder.values).itemgot(2));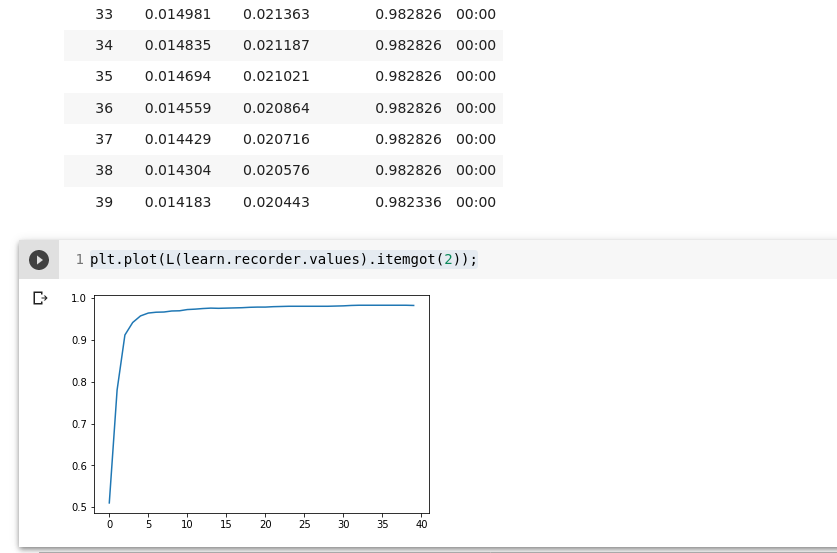
learn.recorder.values[-1][2]Testime 18 kihilist mudelit:
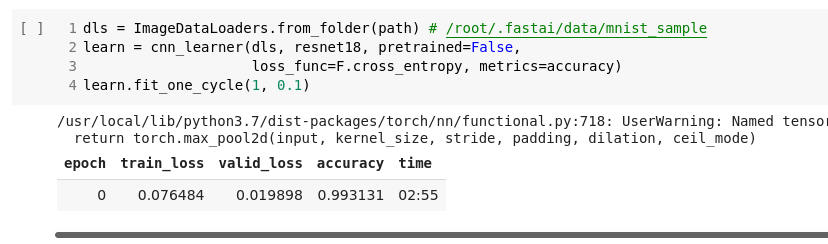
dls = ImageDataLoaders.from_folder(path) # /root/.fastai/data/mnist_sample
learn = cnn_learner(dls, resnet18, pretrained=False,
loss_func=F.cross_entropy, metrics=accuracy)
learn.fit_one_cycle(1, 0.1)