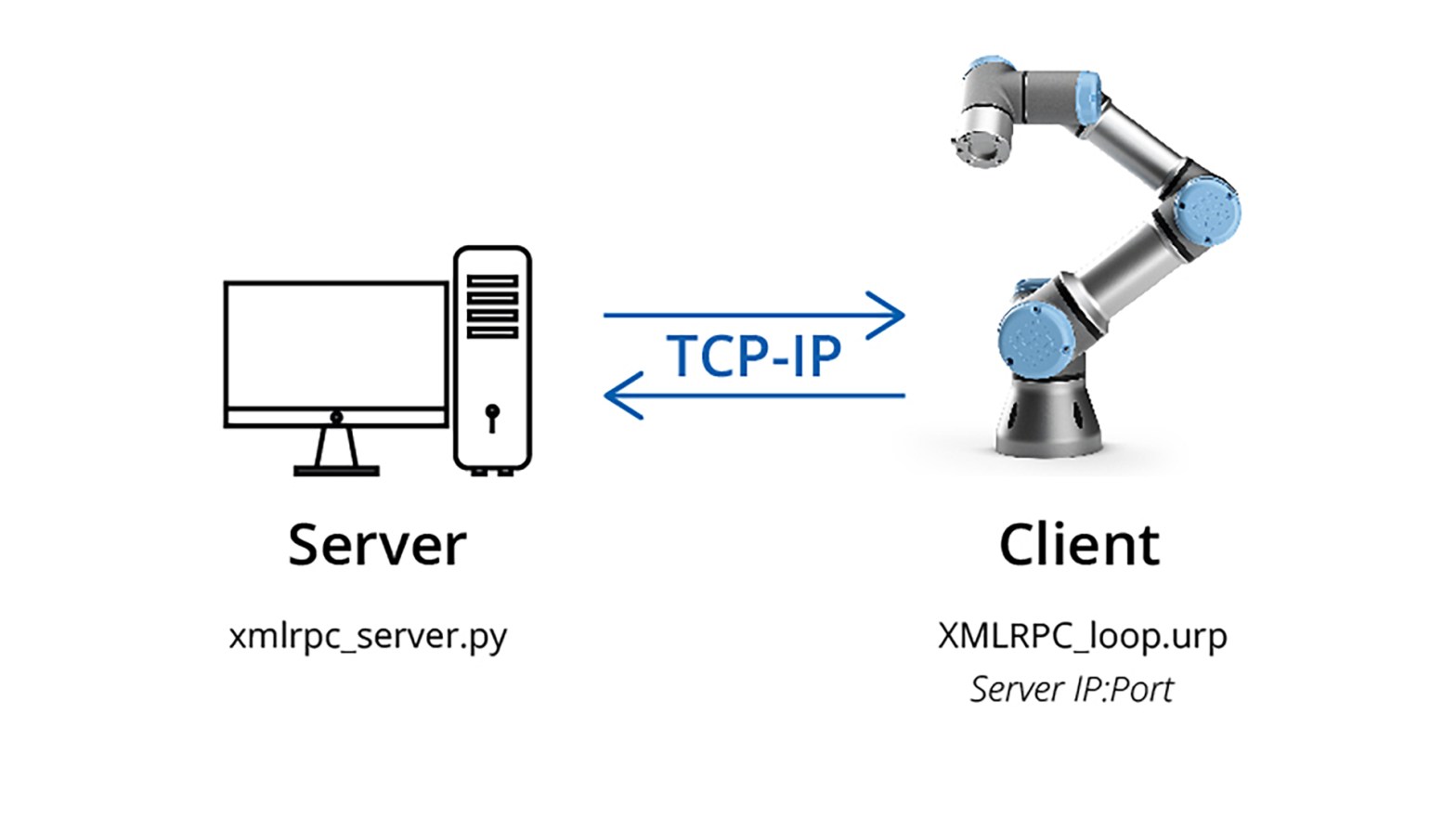
This is my demo code on how to use the XML-RPC to communicate with Universal Robots (UR). UR is the client and PC is the server that runs the Python script. On the demo code, the script only changes the x coordinate. Enable remote control on the robot side. You must change the server IPContinue reading “XML-RPC communication with Universal Robots”
Tag Archives: python
Dark Matplotlib themes/styles
I was searching dark themes for Matplotlib and found these three. And put them here with examples so I can find them faster next time. QB style Website: github.com/quantumblacklabs/qbstyles Install: Example code: ing-theme-matplotlib Website: pypi.org/project/ing-theme-matplotlib/ Install: Example code: mplcyberpunk Website: github.com/dhaitz/mplcyberpunk Install: Example code:
Long-exposure photography in another way

The traditional way to make long-exposure photography is to take photos with a long-duration shutter speed to sharply capture the stationary elements of images while blurring, smearing, or obscuring the moving elements. Long-exposure photography captures one element that conventional photography does not: an extended period of time. (1) One day I watched Scott Manley videoContinue reading “Long-exposure photography in another way”
Continuous image capture from webcam
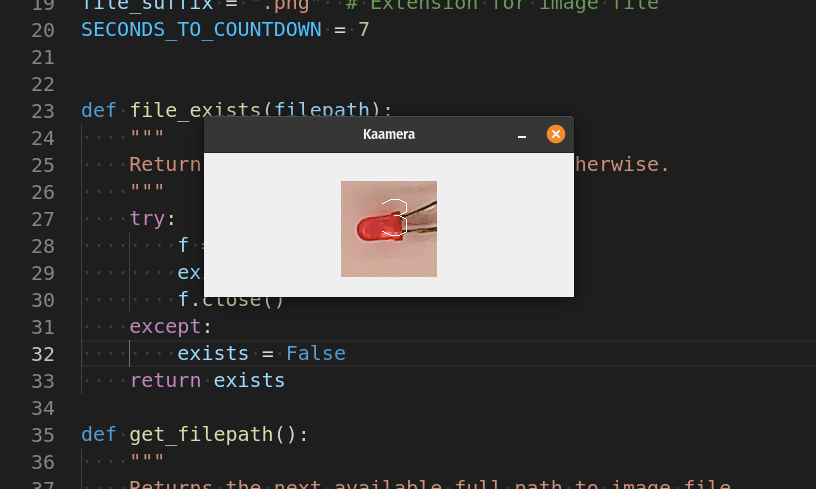
As part of an online course, I currently take “Computer Vision with Embedded Machine Learning” where is need to collect images to make the dataset. I modified the original code so I can use my regular Linux box and webcam, not Raspberry Pi. The programme counts down and saves images every 7 seconds. That isContinue reading “Continuous image capture from webcam”
3. Sügavõpe: andmestikud, kadu, õpisamm ja mudeli parandamine
Minu Colab märkmikk. Fastai originaal Goodle Colab märkmikk. Andmestiku uurimine Andmestiku The Oxford-IIIT Pet Dataset veebileht. Kuidas on andmestik (datset) organiseeritud? Et näha, mis andmestikus on: Andmestik koosneb kahes kataloogist: images ja annotations. Veebileht ütleb, et märkuste (annotations) kataloog sisaldab, infot kus lemmikloomad asuvad, mitte seda mis nad. Kui meid asukoht ei huvita siis võimeContinue reading “3. Sügavõpe: andmestikud, kadu, õpisamm ja mudeli parandamine”
2. MNIST ja sügavõpe
Minu Google Colab märkmik aga parem vaata fastai 04_mnist_basic. Üks tuntumaid andmestike (dataset) on MNIST, mis sisaldab käsitsikirjutatud numbreid. Seda kasutati ühes esimeses praktilises käsitsikirjutatud numbrijärjestuste äratundmise süsteemis Lenet-5 aastal 1998. Laemealla MNIST_SAMPLE andmestiku. See sisaldab ainult numbreid 3 ja 7! Kuvame selle kataloogi (path) sisu: Masinõppe andmestikud (datasets) on tavaliselt jaotatud eraldi kataloogideks: treeningandmestikContinue reading “2. MNIST ja sügavõpe”
Andmekogu loomine jmd-imagescraper abil
Sügavõppe mudelite treenimiseks on vaja palju sildistatud pilte. Üks lihtsamaid mooduseid sellise andmekogu loomiseks on kasutada mõnd otsingumootorit. Otsingumootoriks on DuckDuckGo, mis kasutab Bing otsingumootori koostatud indeksit. Nii, et tulemused on üsna sarnased. Negatiivne külg on ,et leitud vasted on kõik ameerika kesksed ja ei arvesta lokaalsete eripäradega. Näiteks on siga mingi teibi bränd jaContinue reading “Andmekogu loomine jmd-imagescraper abil”
0. Sügavõpe (Deep learning)
Märkmed fast.ai kursusest enda jaoks. Ei ole ülevaatlik ega põhjalik kõikides osades. Originaal märkmik koos inglisekeelsete põhjalike selgitavate tekstiga: 01.intro.ipynb Vajalik on NVIDIA graafikakaart (GPU – Graphics Processing Unit). Need, mis on head mängimiseks ja 3D jaoks sobivad üldiselt ka sügavõppe jaoks. Google Colabis tuleb GPU kasutamine eraldi aktiveerida. Keskkonnaks Jupyter notebook. Kas oma arvutisContinue reading “0. Sügavõpe (Deep learning)”
Python script to generate ridge maps
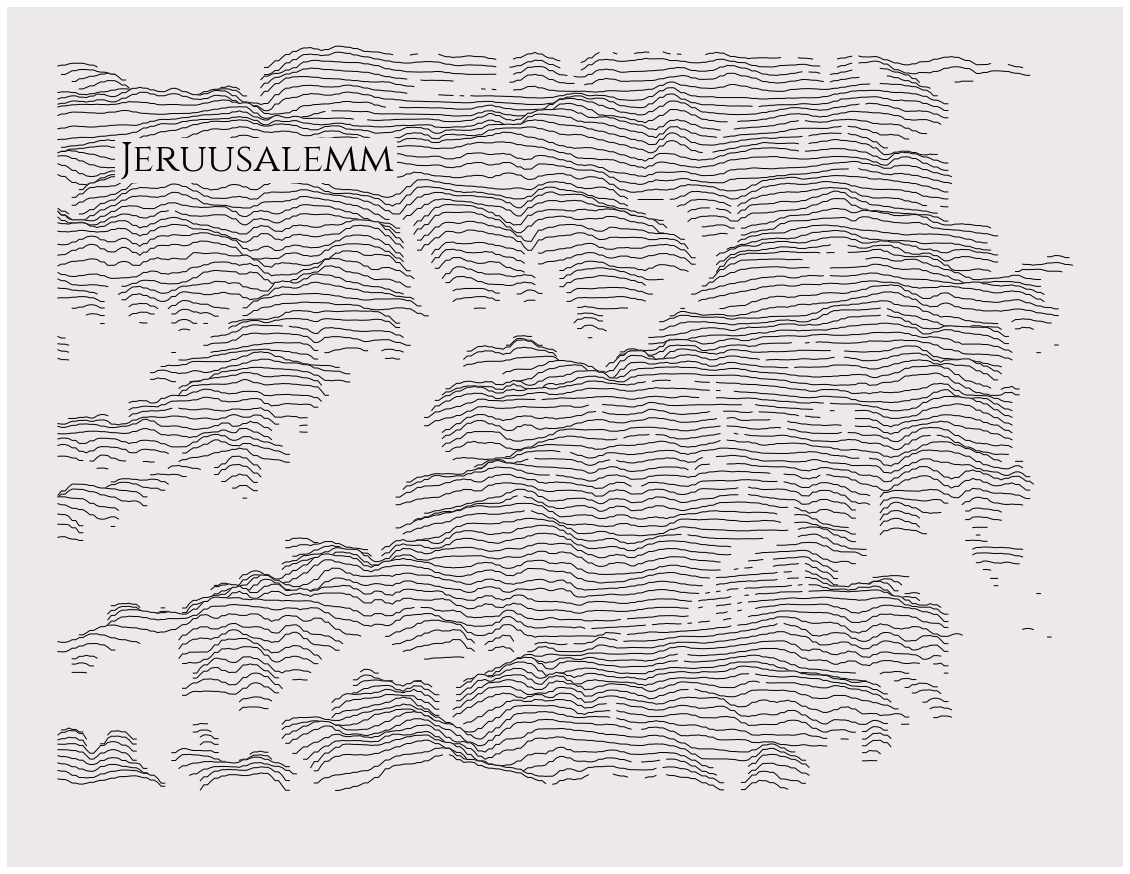
Someone has created a python library to generate ridge maps. All my experiments and code are in this Colab notebook.
The artistic shape detection algorithm

Today I learned one simple shape detection algorithm. In contrast image, it tries to find how many corners on some shapes are. When there is three, then it is a triangle and so on. And draws coloured contour around it. In a controlled environment, it works mostly as supposed. When you released it to theContinue reading “The artistic shape detection algorithm”
Motion detection on the webcam
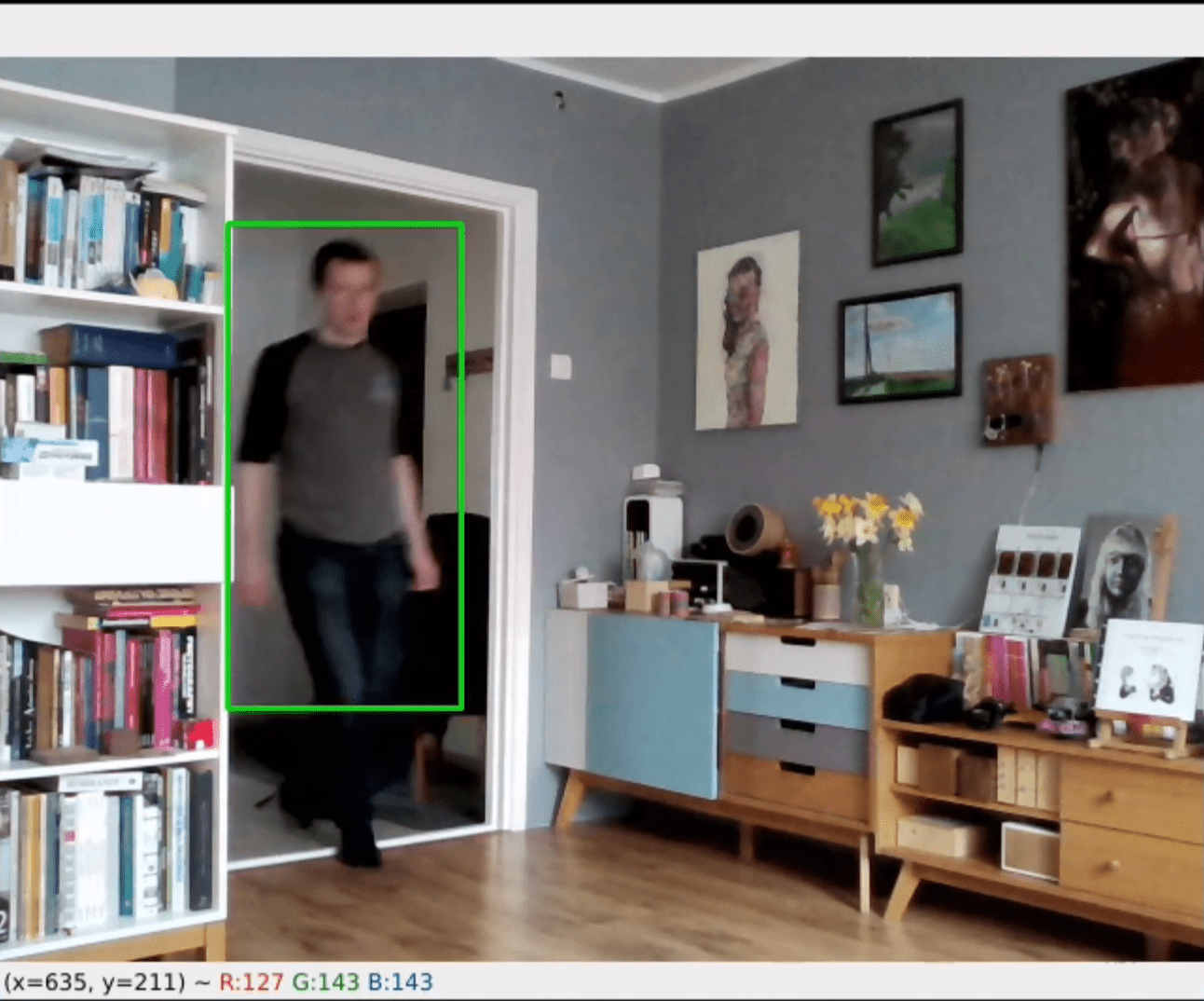
It is surprisingly easy to make a small Python script that takes a webcam or any other video and detects when something is moving there. It uses the OpenCV library. 1. Difference between frames Compares two frames and displays only what are change. The rest is black. 2. Binary image Turn it into binary: onlyContinue reading “Motion detection on the webcam”
Kõige tavalisem värv pildil
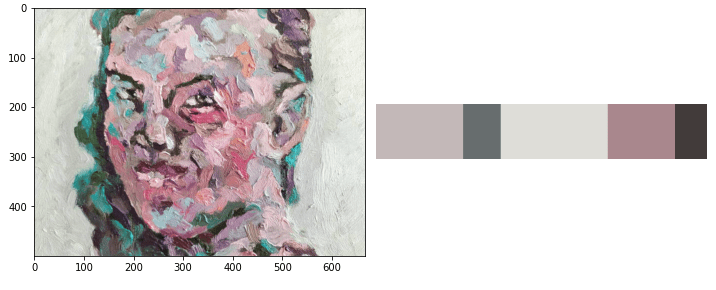
On juhtumid, kus meid ei huvita üksikute pikslite värv. Vaid tahame üldist summeeritud keskmist. Näiteks põllumajanduses saab värvipõhjal hinnata puu või köögivilja küpsusastet. Alustuseks laeme vajalikud teegid: Teeme funktsiooni, mis aitab näidata kahte pilti kõrvuti. Valime pildid: Teeme pilte väiksemaks: Proovime, kas piltide kuvamine töötab: Meetod 1 – keskmine pikslite väärtus Kõige lihtsam meetod onContinue reading “Kõige tavalisem värv pildil”
Sissejuhatus pildiliste andmete töötlusse ja analüüsi 2.
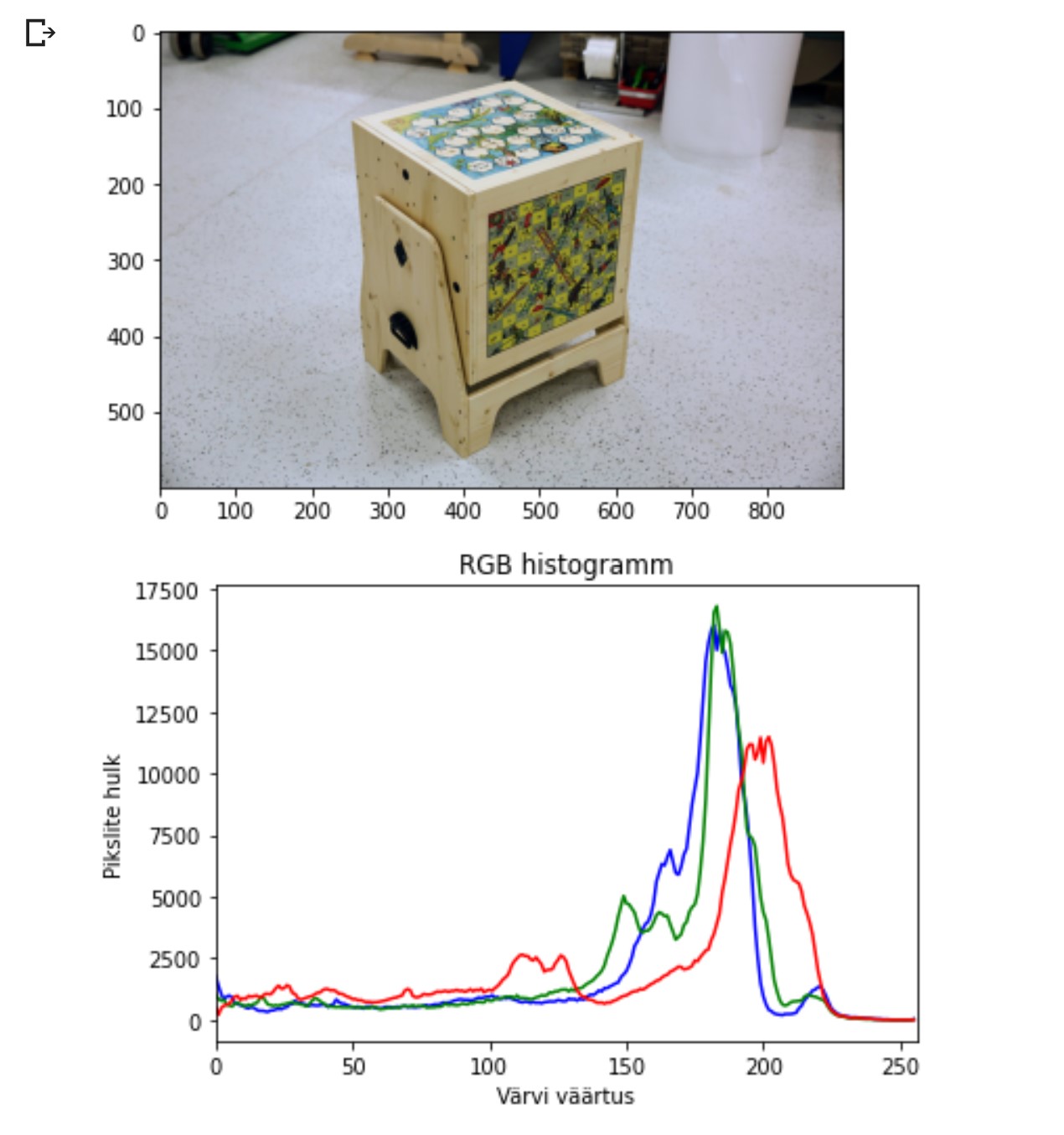
Maskid Maskid on selleks, et mingi osa pildist kinni katta. Filtreerimine Näiteks filtreerime välja pikslid mille väärtus on suurem, kui 200. Ja värvime need mustaks (anname väärtuse 0). Maskide ja filtreerimise näide Kuva ainult punased pikslid mille väärtus on väiksem, kui 235: Ainult rohelised pikslid mille väärtus väiksem, kui 220: Ainult sinised pikslid, mille väärtus väiksem, kui 200: Pilt, kus on kõikContinue reading “Sissejuhatus pildiliste andmete töötlusse ja analüüsi 2.”
Sissejuhatus pildiliste andmete töötlusse ja analüüsi 1.

Antud materjali koostamise eesmärgiks on leida viise, kuidas hinnata objektiivselt pilte ja neil olevat informatsiooni. Et tulemused oleksid mõõdetavad, võrreldavad ja neid saaks teostada automaatselt. Töövahendite tutvustus Jupyter märkmik Jupyter notebook on veebipõhine interaktiivne keskkond, kus saab vaheldumisi kirjutada teksti ja käivitatavaid koodi (python) lahtreid. Et midagi arvutada, töödelda andmeid, kuvada graafikuid jne. Selle kasutamine on väga levinud andmeteadustes, masinõppes ja hariduses. Colab on Google poolt majutatav Jupyter notebook. Python Python on üldotstarbeline programmeerimiskeel. Pythonit peetakse küllaltki lihtsaks keeleks, milles tavaliseltContinue reading “Sissejuhatus pildiliste andmete töötlusse ja analüüsi 1.”
