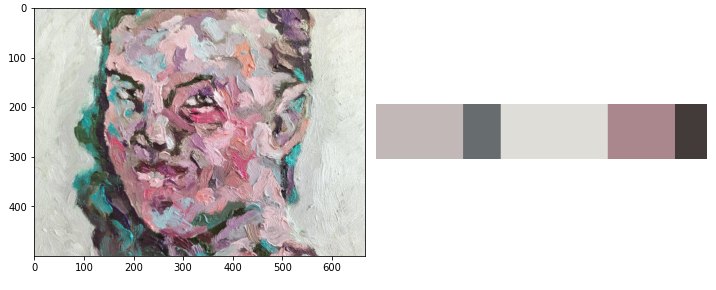On juhtumid, kus meid ei huvita üksikute pikslite värv. Vaid tahame üldist summeeritud keskmist. Näiteks põllumajanduses saab värvipõhjal hinnata puu või köögivilja küpsusastet.
Alustuseks laeme vajalikud teegid:
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
import PIL
from skimage import io
%matplotlib inline
#Kõik pildid on siin kataloogis
kataloog = 'https://raw.githubusercontent.com/taunoe/jupyter-notebooks/main/Pildi-anal%C3%BC%C3%BCs/images/'
Teeme funktsiooni, mis aitab näidata kahte pilti kõrvuti.
def show_img_compar(pilt_1, pilt_2 ):
f, ax = plt.subplots(1, 2, figsize=(10,10))
ax[0].imshow(pilt_1)
ax[1].imshow(pilt_2)
ax[0].axis('on') # Kuva koordinaatteljestik
ax[1].axis('off') # Peida koordinaatteljestik
f.tight_layout()
plt.show()
Valime pildid:
#pilt_1 = cv.imread(kataloog + 'tamm.jpg') # annab errori
pilt_1 = io.imread(kataloog + 'tamm.jpg')
#pilt_1 = cv.cvtColor(pilt_1, cv.COLOR_BGR2RGB) # reastab BGR kihid ümber RGBks
pilt_2 = io.imread(kataloog + 'sinie.jpg')
#pilt_2 = cv.cvtColor(pilt_2, cv.COLOR_BGR2RGB)
Teeme pilte väiksemaks:
dim = (500, 300)
# Pildid väiksemaks
pilt_1 = cv.resize(pilt_1, dim, interpolation = cv.INTER_AREA)
pilt_2 = cv.resize(pilt_2, dim, interpolation = cv.INTER_AREA)
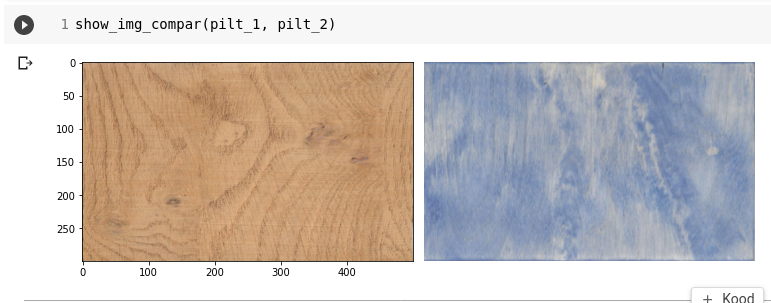
Proovime, kas piltide kuvamine töötab:
Meetod 1 – keskmine pikslite väärtus
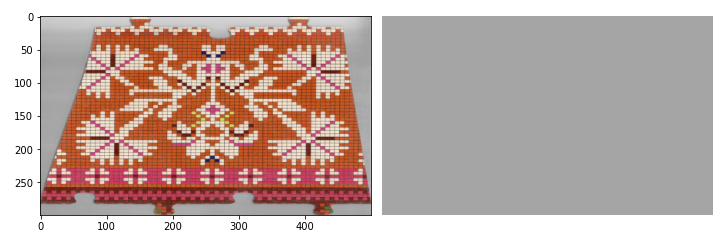
Kõige lihtsam meetod on leida pikslite keskmised väärtused. Kasutades teegist numpy average funktsiooni leidmaks keskmise piksli väärtus.
Selline meetod võib anda ebatäpseid tulemusi. Eriti, kui pildi pinnal on suuri kontrasti (heledate ja tumedate alade) erinevusi. Tamme tekstuuri puhul on aga tulemus üsna usutav.
img_temp = pilt_1.copy()
img_temp[:,:,0], img_temp[:,:,1], img_temp[:,:,2] = np.average(pilt_1, axis=(0,1))
show_img_compar(pilt_1, img_temp)

img_temp = pilt_2.copy()
img_temp[:,:,0], img_temp[:,:,1], img_temp[:,:,2] = np.average(pilt_2, axis=(0,1))
show_img_compar(pilt_2, img_temp)

pilt_3 = io.imread(kataloog + 'muster.jpg') # impordime pildi
pilt_3 = cv.resize(pilt_3, dim, interpolation = cv.INTER_AREA) # muudame suurust
img_temp = pilt_3.copy() # teeme koopia
img_temp[:,:,0], img_temp[:,:,1], img_temp[:,:,2] = np.average(pilt_3, axis=(0,1)) # arvutame keskmise
show_img_compar(pilt_3, img_temp) # kuvame tulemused
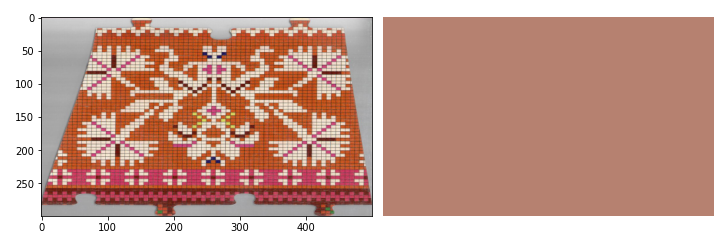
Meetod 2 – levinuima värviga pikslid
Teine meetod on natuke täpsem, kui esimene. Loeme iga piksli väärtuse esinemise sagedust.
img_temp = pilt_3.copy()
unique, counts = np.unique(img_temp.reshape(-1, 3), axis=0, return_counts=True)
img_temp[:,:,0], img_temp[:,:,1], img_temp[:,:,2] = unique[np.argmax(counts)]
show_img_compar(pilt_3, img_temp)
img_temp_2 = pilt_2.copy()
unique, counts = np.unique(img_temp_2.reshape(-1, 3), axis=0, return_counts=True)
img_temp_2[:,:,0], img_temp_2[:,:,1], img_temp_2[:,:,2] = unique[np.argmax(counts)]
show_img_compar(pilt_2, img_temp_2)

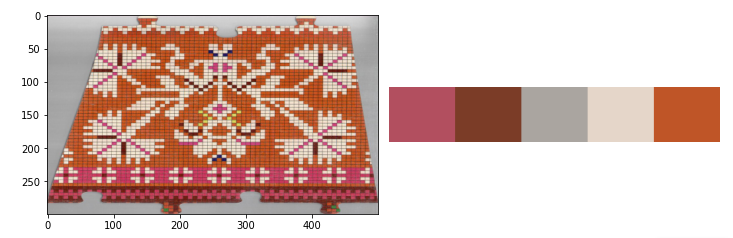
Meetod 3 – levinumad värvi grupid pildil
K-keskmiste klasteradmine – jagame pikslid värvi läheduse järgi klastritesse. Ja vaatame, mis on keskmine värv klastrites.
from sklearn.cluster import KMeans
clt = KMeans(n_clusters=5) # Klastrite arv
Funktsioon värvipaletti koostamiseks.
def palette(clusters):
width=300
height=50
palette = np.zeros((height, width, 3), np.uint8)
steps = width/clusters.cluster_centers_.shape[0]
for idx, centers in enumerate(clusters.cluster_centers_):
palette[:, int(idx*steps):(int((idx+1)*steps)), :] = centers
return palette
clt_1 = clt.fit(pilt_3.reshape(-1, 3))
show_img_compar(pilt_3, palette(clt_1))
clt_2 = clt.fit(pilt_2.reshape(-1, 3))
show_img_compar(pilt_2, palette(clt_2))

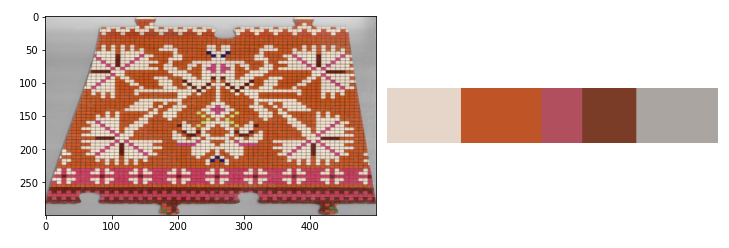
Meetod 4 – levinumad värvi grupid proportsionaalselt
Sisuliselt sama, mis eelmine aga leitud värve kuvab proportsionaalselt selle levikuga. Kui mingit värvi on rohkem, siis selle ristkülik on ka suurem ja vastupidi.
Abifunktsioon värvipaletti kuvamiseks:
from collections import Counter
def palette_perc(k_cluster):
width = 300
height = 50
palette = np.zeros((height, width, 3), np.uint8)
n_pixels = len(k_cluster.labels_)
counter = Counter(k_cluster.labels_) # count how many pixels per cluster
perc = {}
for i in counter:
perc[i] = np.round(counter[i]/n_pixels, 2)
perc = dict(sorted(perc.items()))
#for logging purposes
#print(perc)
#print(k_cluster.cluster_centers_)
step = 0
for idx, centers in enumerate(k_cluster.cluster_centers_):
palette[:, step:int(step + perc[idx]*width+1), :] = centers
step += int(perc[idx]*width+1)
return palette
clt_1 = clt.fit(pilt_3.reshape(-1, 3))
show_img_compar(pilt_3, palette_perc(clt_1))
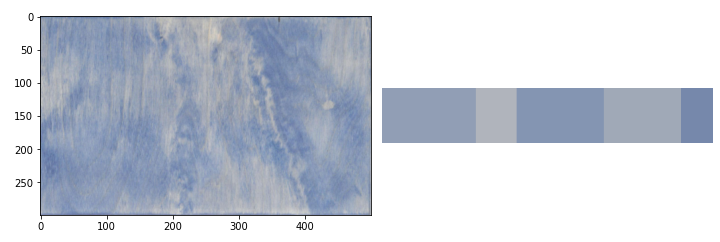
clt_2 = clt.fit(pilt_2.reshape(-1, 3))
show_img_compar(pilt_2, palette_perc(clt_2))
pilt_4 = io.imread(kataloog + 'klaster1.jpg') # Impordime pildi
pilt_4 = cv.resize(pilt_4, dim, interpolation = cv.INTER_AREA) # Pilt väiksemaks
clt_4 = clt.fit(pilt_4.reshape(-1, 3))
show_img_compar(pilt_4, palette_perc(clt_4))

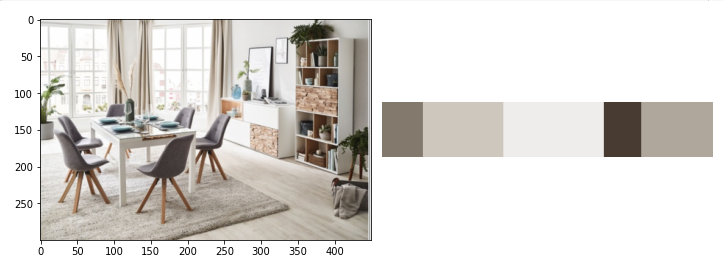
pilt_5 = io.imread(kataloog + 'wermo1.png') # Impordime pildi
#pilt_5 = cv.resize(pilt_5, dim, interpolation = cv.INTER_AREA) # Pilt väiksemaks
clt_5 = clt.fit(pilt_5.reshape(-1, 3))
show_img_compar(pilt_5, palette_perc(clt_5))
pilt_7 = io.imread(kataloog + 'kevad.jpg') # Impordime pildi
#pilt_7 = cv.resize(pilt_6, (500, 500) , interpolation = cv.INTER_AREA) # Pilt väiksemaks
clt_7 = clt.fit(pilt_7.reshape(-1, 3))
show_img_compar(pilt_7, palette_perc(clt_7))