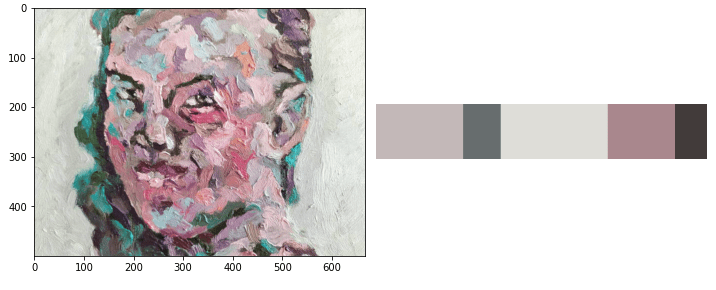
On juhtumid, kus meid ei huvita üksikute pikslite värv. Vaid tahame üldist summeeritud keskmist. Näiteks põllumajanduses saab värvipõhjal hinnata puu või köögivilja küpsusastet. Alustuseks laeme vajalikud teegid: Teeme funktsiooni, mis aitab näidata kahte pilti kõrvuti. Valime pildid: Teeme pilte väiksemaks: Proovime, kas piltide kuvamine töötab: Meetod 1 – keskmine pikslite väärtus Kõige lihtsam meetod onContinue reading “Kõige tavalisem värv pildil”
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
