Sügavõppe mudelite treenimiseks on vaja palju sildistatud pilte. Üks lihtsamaid mooduseid sellise andmekogu loomiseks on kasutada mõnd otsingumootorit. Otsingumootoriks on DuckDuckGo, mis kasutab Bing otsingumootori koostatud indeksit. Nii, et tulemused on üsna sarnased. Negatiivne külg on ,et leitud vasted on kõik ameerika kesksed ja ei arvesta lokaalsete eripäradega. Näiteks on siga mingi teibi bränd jaContinue reading “Andmekogu loomine jmd-imagescraper abil”
Tag Archives: jupyter notebook
1. Sügavõpe (Deep leartning)
Lühi konspekt originaal fastai märkmikust 02_production.ipynb Masinnägemine Computer vision object recognition – asjade äratundmine object detection – asjade tuvastamine: asukoht, nimi segmentation – iga piksel kategoriseeritakse selle järgi, mis objekti osa ta on. out-of-domain data – Sügavõppe mudelid ei ole üldiselt head nende piltide äratundmisel, mis erinevad oluliselt struktuuri või stiili poolest nendest piltidest millega tedaContinue reading “1. Sügavõpe (Deep leartning)”
Kõige tavalisem värv pildil
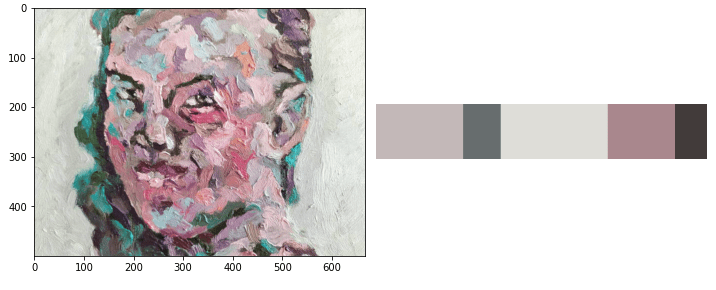
On juhtumid, kus meid ei huvita üksikute pikslite värv. Vaid tahame üldist summeeritud keskmist. Näiteks põllumajanduses saab värvipõhjal hinnata puu või köögivilja küpsusastet. Alustuseks laeme vajalikud teegid: Teeme funktsiooni, mis aitab näidata kahte pilti kõrvuti. Valime pildid: Teeme pilte väiksemaks: Proovime, kas piltide kuvamine töötab: Meetod 1 – keskmine pikslite väärtus Kõige lihtsam meetod onContinue reading “Kõige tavalisem värv pildil”
Sissejuhatus pildiliste andmete töötlusse ja analüüsi 2.
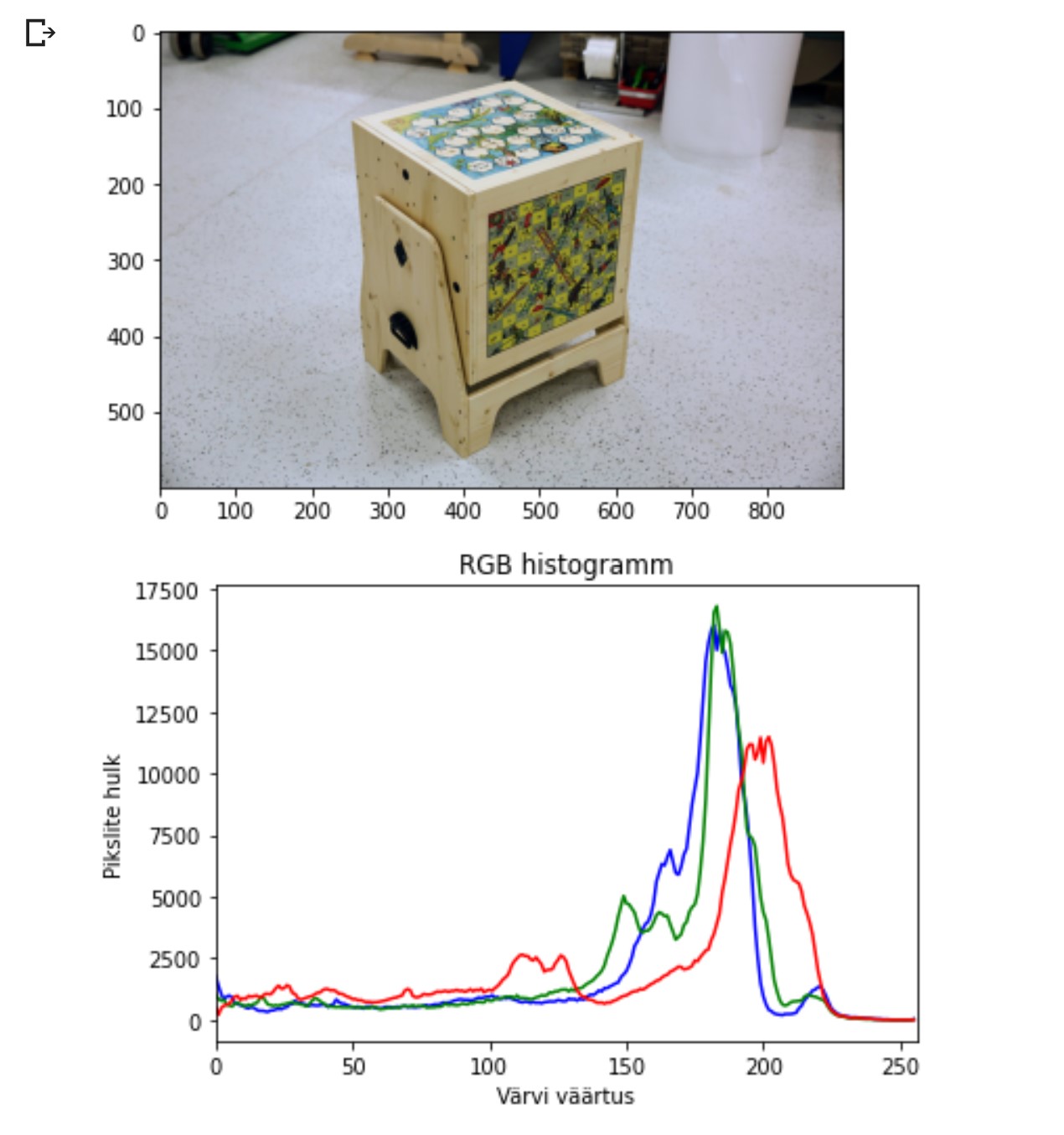
Maskid Maskid on selleks, et mingi osa pildist kinni katta. Filtreerimine Näiteks filtreerime välja pikslid mille väärtus on suurem, kui 200. Ja värvime need mustaks (anname väärtuse 0). Maskide ja filtreerimise näide Kuva ainult punased pikslid mille väärtus on väiksem, kui 235: Ainult rohelised pikslid mille väärtus väiksem, kui 220: Ainult sinised pikslid, mille väärtus väiksem, kui 200: Pilt, kus on kõikContinue reading “Sissejuhatus pildiliste andmete töötlusse ja analüüsi 2.”
Sissejuhatus pildiliste andmete töötlusse ja analüüsi 1.

Antud materjali koostamise eesmärgiks on leida viise, kuidas hinnata objektiivselt pilte ja neil olevat informatsiooni. Et tulemused oleksid mõõdetavad, võrreldavad ja neid saaks teostada automaatselt. Töövahendite tutvustus Jupyter märkmik Jupyter notebook on veebipõhine interaktiivne keskkond, kus saab vaheldumisi kirjutada teksti ja käivitatavaid koodi (python) lahtreid. Et midagi arvutada, töödelda andmeid, kuvada graafikuid jne. Selle kasutamine on väga levinud andmeteadustes, masinõppes ja hariduses. Colab on Google poolt majutatav Jupyter notebook. Python Python on üldotstarbeline programmeerimiskeel. Pythonit peetakse küllaltki lihtsaks keeleks, milles tavaliseltContinue reading “Sissejuhatus pildiliste andmete töötlusse ja analüüsi 1.”
