Lühi konspekt originaal fastai märkmikust 02_production.ipynb
Masinnägemine Computer vision
- object recognition – asjade äratundmine
- object detection – asjade tuvastamine: asukoht, nimi
- segmentation – iga piksel kategoriseeritakse selle järgi, mis objekti osa ta on.
- out-of-domain data – Sügavõppe mudelid ei ole üldiselt head nende piltide äratundmisel, mis erinevad oluliselt struktuuri või stiili poolest nendest piltidest millega teda on treenitud. Näiteks, kui treening andmetes polnud mustvalgeid pilte võib mudel nendega halvasti toimida. Või näiteks käsitsi joonistatud pildid
- data augmentation – protsess, kus genereeritakse varieeruvustega uus pilte olemas olevatest andmetest. Neid näiteks pöörates, muutes heledust jne. Et vähendada vajadust käsitsi sildistada (label) paljusid andmehulki.
- GPU on vajalik mudeli treenimiseks aga , kui mudel on valmis siis pole see enam alati vajalik.
Natural language processing (NLP)
Jupyter Notebookis abi kuvamiseks kirjuta koodo lahtrisse ??funktsiooninimi Näide: ??verify_images
Karud liikide klassifitseerimine
Seadistamine Google Colabis algab fastbooki paigaldamisega,
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.widgets import *
1. Andmekogu loomine Bing Image Search abil
Loo tasuta Microsoft Azure konto.
Ja otsi üles võtti (Key1).
key = os.environ.get('AZURE_SEARCH_KEY', 'e04722cgfdhghdfghgfhfdhdfhdfh772461') # võti näeb u. selline välja
Vaatame kas töötab:
search_images_bing
Sooritame otsingu otsisõnaga ‘grizzly bear’. Tasuta saame korraga otsida kuni 150 pilti.
results = search_images_bing(key, 'grizzly bear')
ims = results.attrgot('contentUrl')
len(ims)
Laeme ühe pildi alla:
# Loome kataloogi image
dir = Path('image')
if not dir.exists():
dir.mkdir()
dest = 'image/grizzly.jpg'
download_url(ims[0], dest)
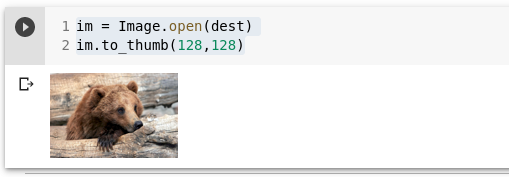
Kuvame pildi:
im = Image.open(dest)
im.to_thumb(128,128)
Kui see töötab, kasutame fastai’s download_images, et allalaadida kõik URLid kõigi meie otsingu terminite kohta. Paneme terminite järgi erinevatesse kataloogidesse. Skript loob kataloogid eraldi karu liikidele.
bear_types = 'grizzly','black','teddy'
path = Path('bears')
# Kui 'bears' kataloogi ei ole
if not path.exists():
path.mkdir()
# karu tüübid
for beartype in bear_types:
dest = (path/beartype)
dest.mkdir(exist_ok=True)
dir = os.listdir(dest)
# Kui kataloog on tühi
if len(dir) == 0:
results = search_images_bing(key, f'{beartype} bear')
download_images(dest, urls=results.attrgot('contentUrl'))
# Hiljem tekib probleeme, kui png fail ei ole RGBA
for beartype in bear_types:
dest = (path/beartype)
# convert images to RGBA
for image in os.listdir(dest):
full = str(dest) +"/"+ image
try:
im = Image.open(full)
# Kui on png image
if im.format == 'PNG':
# ja ei ole RGBA
if im.mode != 'RGBA':
im.convert("RGBA").save(f"{dest+image}2.png")
except:
print(full)
fns = get_image_files(path)
fns
Kontrollime kas kõik pildid said vigadeta allalaetud:
failed = verify_images(fns)
failed
Vigaste piltide eemaldamine:
failed.map(Path.unlink);
2. DataLoaders
DataLoaders on objekt, mis hoiab andmehulka, et see oleks kättesaav treenimiseks (train) ja valideerimiseks (valid).
Peame ütlema fastai’le nelja asja:
- Mis tüüpi andmetega me töötame
- Kuidas saada andmete loendit
- Kuidas neid sildistada
- Kuidas luua valideerimis andekogu
Loob DataBlock objekti. See on mall, mille järgi hiljem loome DataLoadersi:
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock), # types for the independent and dependent variables
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))
blocks=(ImageBlock, CategoryBlock) – loome enniku (tuple), kus määrame, mis andme tüüpe tahame sõltumatu (independent) ja sõltuva (dependent) muutuja jaoks.
Sõltumatut muutujat (independent variable) on see mida kasutame ennustamiseks. Antud juhul pildid.
Sõltuv muutuja (dependent variable) on meie sihtmärk/eesmärk/tulemus. Antud juhul piltide katekoogiad ehk karu tüübid.
get_items=get_image_files – Loob listi kõigis kataloogis olevatest piltidest.
splitter=RandomSplitter(valid_pct=0.2, seed=42) – Jagame juhuslikult andmehulha treening ja valideerimis osaks. Seeme (seed) on juhuslike numbrite genereerimise alguspunkt ja see tagab, et saame igakord sama listi.
get_y=parent_label – Siin ütleme. kuidas luua silid meie andmekogule. parent_label on funktsioon, mis tagastab kataloogi nime, milles fail on. Sõltumatut muutujat (independent variable) tähistatakse tavaliselt x’iga. Sõltuv muutuja (dependent variable) y’ga.
item_tfms=Resize(128) – Muudame kõik pildid sama suureks. Pilte ei söödeta mudeliise mitte üksikult vaid väikeste hulkadena (mini-batch). Tensor on suur grupp pilte. Item transforms on funktsioon (antud juhul resize), mis töötleb igat andme ühikut (pilti).
Siin toimub tegelik DataLoadersi loomi. Failide asukoht (path) on meil eespool defineeritud.
dls = bears.dataloaders(path)
DataLoader söödab pilte GPU’le mitmekaupa. Ühes tensortis 64 pilti.
Kuvame neist mõned:
dls.valid.show_batch(max_n=4, nrows=1)

Vaikimisi Resize kropip pildid ruutudeks. Aga nii võib mingi oluline osa pildist kadumaminna.
Teiste võimalustena saab pildid venitada/suruda ruututeks või vähendada pildid, kuni mahuvad ruudu sisse ja täita ülejäänud pildi osa nullidega (mustaga).
# Venitamine
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)

# vähendamine ja mustaga täitmine
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros'))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)

Probleemid:
Kui venitame pilte, siis muudame nende kuju ja asjad näevad välja teistsugused, kui nad tegelikult on.
Kui kropime, siis võib mingi oluline osa infost kaduma minna.
Kui vähendame ja täidame tühjad alad mustaga siis raiskame arvutusressurssi tühjade pildi alade jaoks. Ja lisaks on tegelikud pildid veel väiksema resolutsiooniga, kui muidu, mis võib viia ebatäpsuseni.
Parem lahendus on kasutada igal epohhil juhuslikult kroppida erinev pildi osa. Selle tulemusena saab mudel paremini keskenduda erinevatele pildi osade äratundmisele. Ja see on lähemal reaalsetele andmetele, kus asjad ei ole alati pildi keskel ja võivad olla erineva suurusega.
Asendame Resize uue funktsiooniga RandomResizedCrop. Olulised osad on min_scale ja unique=True – sama pilti korratakse erinevate versioonidega. See on osa andmete täiendamise tehnikast (data augmentation).
bears = bears.new(item_tfms=RandomResizedCrop(128, min_scale=0.3))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=4, nrows=1, unique=True)

Andmete täiendamine Data Augmentation
On tehnika suurendamaks varieeruvust treening andmetes luues juhuslike erinevusi. Nii, et nad näiksid erinevad aga ei kaotaks oma sisu. Näited tehnikatest: keeramine, peegeldamine, perspektiivi muutmine ja painutamine, heleduse ja kontrasti muutmine.
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True)

2. DataLoaders
DataLoaders on objekt, mis hoiab andmehulka, et see oleks kättesaav treenimiseks (train) ja valideerimiseks (valid).
Peame ütlema fastai’le nelja asja:
- Mis tüüpi andmetega me töötame
- Kuidas saada andmete loendit
- Kuidas neid sildistada
- Kuidas luua valideerimis andekogu
Loob DataBlock objekti. See on mall, mille järgi hiljem loome DataLoadersi:
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock), # types for the independent and dependent variables
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))
blocks=(ImageBlock, CategoryBlock) – loome enniku (tuple), kus määrame, mis andme tüüpe tahame sõltumatu (independent) ja sõltuva (dependent) muutuja jaoks.
Sõltumatut muutujat (independent variable) on see mida kasutame ennustamiseks. Antud juhul pildid.
Sõltuv muutuja (dependent variable) on meie sihtmärk/eesmärk/tulemud. Antud juhul piltide katekoogiad ehk karu tüübid.
get_items=get_image_files – Loob listi kõigis kataloogis olevatest piltidest.
splitter=RandomSplitter(valid_pct=0.2, seed=42) – Jagame juhuslikult andmehulha treening ja valideerimis osaks. Seeme (seed) on juhuslike numbrite genereerimise alguspunkt ja see tagab, et saame igakord sama listi.
get_y=parent_label – Siin ütleme. kuidas luua silid meie andmekogule. parent_label on funktsioon, mis tagastab kataloogi nime, milles fail on. Sõltumatut muutujat (independent variable) tähistatakse tavaliselt x’iga. Sõltuv muutuja (dependent variable) y’ga.
item_tfms=Resize(128) – Muudame kõik pildid sama suureks. Pilte ei söödeta mudeliise mitte üksikult vaid väikeste hulkadena (mini-batch). Tensor on suur grupp pilte. Item transforms on funktsioon (antud juhul resize), mis töötleb igat andme ühikut (pilti).
Siin toimub tegelik DataLoadersi loomi. Failide asukoht (path) on meil eespool defineeritud.
dls = bears.dataloaders(path)
DataLoader söödab pilte GPU’le mitmekaupa. Ühes tensortis 64 pilti.
Kuvame neist mõned:
Vaikimisi Resize kropip pildid ruutudeks. Aga nii võib mingi oluline osa pildist kadumaminna.
Teiste võimalustena saab pildid venitada/suruda ruututeks või vähendada pildid, kuni mahuvad ruudu sisse ja täita ülejäänud pildi osa nullidega (mustaga).
# Venitamine
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)
# vähendamine ja mustaga täitmine
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros'))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)
Probleemid:
Kui venitame pilte, siis muudame nende kuju ja asjad näevad välja teistsugused, kui nad tegelikult on.
Kui kropime, siis võib mingi oluline osa infost kaduma minna.
Kui vähedame ja täidame tühjad alad mustaga siis raiskame arvutusressurssi tühjade pildi alade jaoks. Ja lisaks on tegelikud pildid veel väiksema resolutsiooniga, kui muidu, mis võib viia ebatäpsuseni.
Parem lahendus on kasutada igal epohhil juhuslikult kroppida erinev pildi osa. Selle tulemusena saab mudel paremini keskenduda erinevatele pildi osade äratundmisele. Ja see on lähemal reaalsetele andmetele, kus asjad ei ole alati pildi keskel ja võivad olla erineva suurusega.
Asendame Resize uue funtksiooniga RandomResizedCrop. Olulised osad on min_scale ja unique=True – sama pilti korratakse erinevate versioonidega. See on osa andmete täiendamise tehnikast (data augmentation).
bears = bears.new(item_tfms=RandomResizedCrop(128, min_scale=0.3))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=4, nrows=1, unique=True)
Andmete täiendamine Data Augmentation
On tehnika suurendamaks varieeruvust treening andmetes luues juhuslike erinevusi. Nii, et nad näiksid erinevad aga ei kaotaks oma sisu. Näited tehnikatest: keeramine, peegeldamine, perspektiivi muutmine ja painutamine, heleduse ja kontrasti muutmine.
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True)
3. Treenimine
Meil ei ole palju andmeid. 150 pilti igast karu liigist. Seega kasutame RandomResizedCrop pildi suurusega 224px, mis standart suurus ja kasutame ka aug_transforms:
bears = bears.new(
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
dls = bears.dataloaders(path)
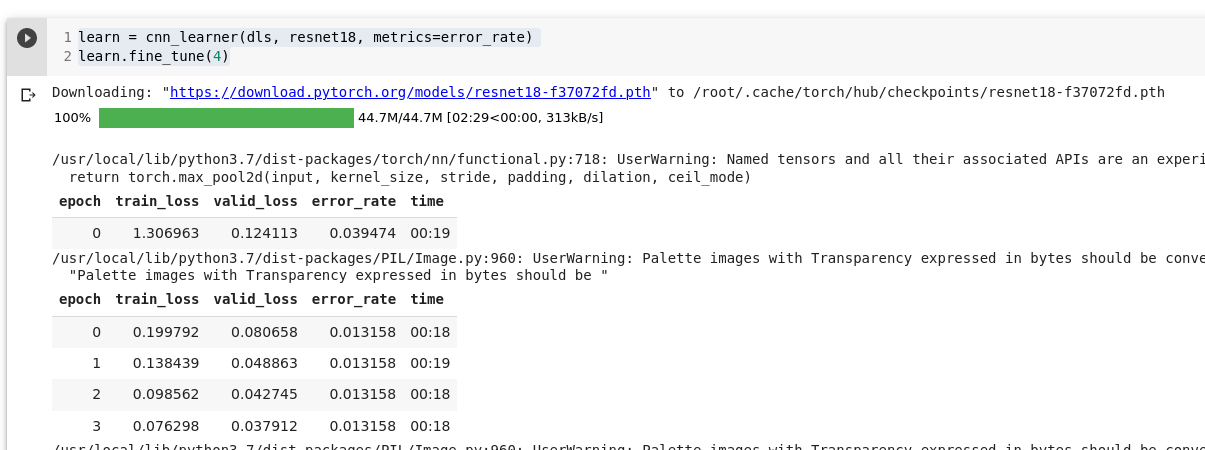
Alustame treenimisega ja häälestame (fine_tune):
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)
Vaatame milliste piltidega on mudelil kõige rohkem raskusi. Visualiseerimiseks kasutame confusion matrix
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
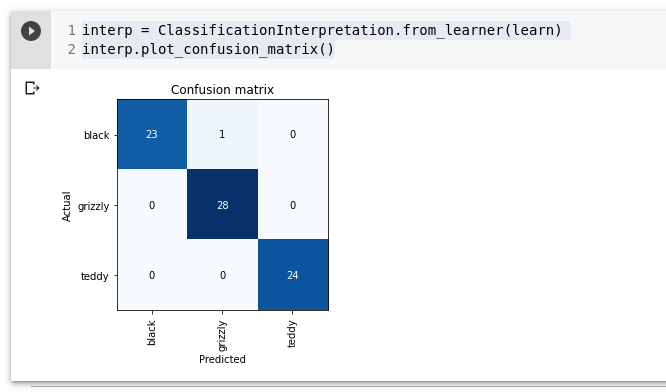
Read esindavad kõiki black, grizzly ja teddy karusid meie andmehulgas.
Tulbad näitavad mida mudel ennustas.
Diagonaal maatriksil näitab õigeid ennustusi ja mis ei ole diagonaalil näitab ebaõigeid klassi määramisi.
Loss on number, mis on suurem, kui mudel eksib (eriti kui ta on kindel oma ebaõigetes vastustes) või kui mudelil on õigus aga puudub kindlus, et on õige.
plot_top_losses näitab kõigesuurema loss arvuga pilte.
interp.plot_top_losses(6, nrows=2)

Võib ette tulla valesti sildistatud pilte

4. Andmete korrastamine/puhastamine
Fastai sisaldab graafilist liidest (GUI) ImageClassifierCleaner andmete puhastamiseks. Kus saab valitud pilte kas kustutada või muuta kategooriat.
cleaner = ImageClassifierCleaner(learn)
cleaner
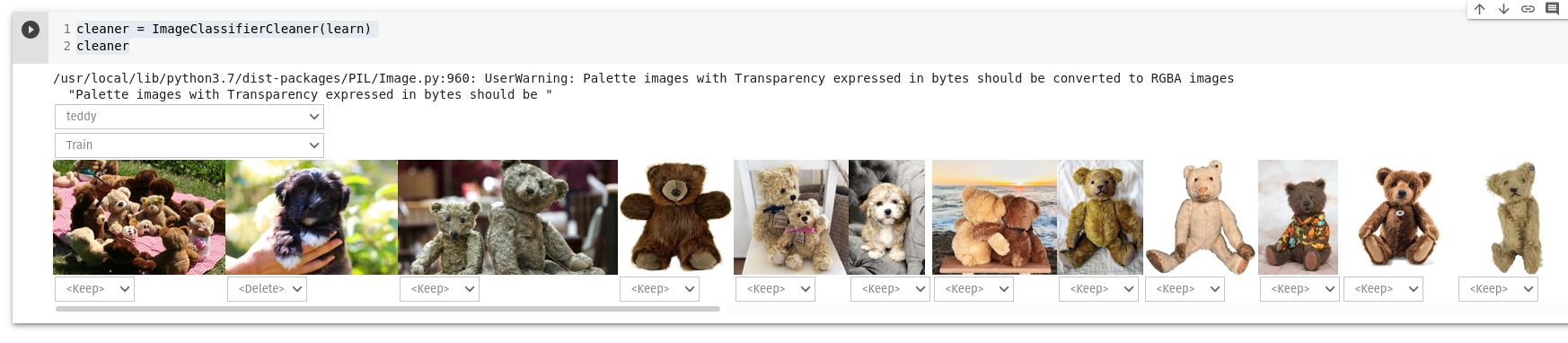
Et kustutada (unlink) valitud pilte:
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
Et liigutada valitud pilte teise katekooriasse:
for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)
Seejärel treenime uuesti puhastatud andmetega.
5. Mudeli eksportimine
Valmis mudel koosneb kahest osast:
- Arhitektuur
- Treenitud parameetrid
Mudeli salvestamiseks failiks “export.pkl”:
learn.export()
Kontrollime, kas fail on olemas:
path = Path()
path.ls(file_exts='.pkl')
6. Järeldamin (inference)
Kui me enam ei tree mudelit ja kasutame seda ennustuste (predictions) saamiseks kutsutakse seda järeldamiseks (inference).
Et kasutada eksporditud mudelit järelduste tegemiseks tuleb see kõigepealt sisse laadida:
learn_inf = load_learner(path/'export.pkl')
Et teada saada mida mudel arvab mingist pildist tuleb see talle, ette anda.
pilt = ('image/grizzly.jpg')
learn_inf.predict(pilt)

Näeme kolme asja: ennustatud kategooriat, ennustatud kategooria indeksit, ja iga kategooria tõenäosust.
Et näha, mis kategooriad on mudelis:
learn_inf.dls.vocab
7. Veebirakendus
Hobiprojektide jaoks on lihtsaim ja tasuta viis luua veebirakendus kasutada Binderit.
- Lae märkmikk GitHubi
- Lisa GitHuvi koodivaramu URL Binder’isse
- File valik rippmenüüs muuda URLiks
- URL kirjuta
/voila/render/name.ipynb, kus name on sinu märkmiku nimi - click clickboard copy URL
- Launch
Siin on näidisrakenduse kood: github.com/fastai/bear_voila
Selleks vajame:
- IPython widgets (ipywidgets)
- Voilà (Ei tööta Google Colabis!)
Voila on nagu Jupyteri märkmikud aga peidab ära kõik sisend koodilahtrid (shells) ja näitab ainult nende väljundit + markdowni lahtreid. Veebirakenduse nägemiseks muuta brauseri URLis “notebooks” -> “voila/render”
Valmis mudel on funktsioon mida saab välja kutsuda (pred,pred_idx,probs = learn.predict(img)) igas pythoni koodis.
