Minu Colab märkmikk. Fastai originaal Goodle Colab märkmikk.
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.all import *Andmestiku uurimine
Andmestiku The Oxford-IIIT Pet Dataset veebileht.
path = untar_data(URLs.PETS) # AndmestikKuidas on andmestik (datset) organiseeritud?
Path.BASE_PATH = pathEt näha, mis andmestikus on:
path.ls()Andmestik koosneb kahes kataloogist: images ja annotations. Veebileht ütleb, et märkuste (annotations) kataloog sisaldab, infot kus lemmikloomad asuvad, mitte seda mis nad. Kui meid asukoht ei huvita siis võime seda kataloogi praegu eirata.
Vaatame piltide kataloogi (images/):
(path/"images").ls()
Kuvatakse pilte arv (#7393) ja algust failide nimekirjast. Näeme, et failinimi koosneb tõu nimest numbrist ja faililaiendist. Koerte tõud on algavad väikse tähega ja kassid suure tähega.
Valime ühe faili:
fname = (path/"images").ls()[4]
fnameRegulaaravaldised
Kasutame regulaaravaldisi (regular expressions), et failinimest eralda ainult tõu nimi.
re.findall(r'(.+)_\d+.jpg$', fname.name)Kasutame regulaaravaldist, et märgistada (label) kogu andmestik (dataset).
pets = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = pets.dataloaders(path/"images")Eelnev suuruste muutmine (Presizing)
DataBlock koodis on:
item_tfms=Resize(460)
batch_tfms=aug_transforms(size=224, min_scale=0.75)
Oleks hea, kui meie pildid oleks kõik ühesuurused.
Esialgu jätta pildid suhteliselt suureks (st suuremaks, kui treenimiseks kasutatavd). Et näiteks pilte keerates ei jääks hiljem nurkatessse tühjad pikslid.
item_tfms – kärpida (crop) pildid kas täis laiuses või kõrguses. Treening andmestiku valitakse kärpimise asukoht juhuslikult. Valiteerimisandmestiku alati keskmine ruut.
batch_tfms – juhuslik kärpimine ja andmete täiendamine (augmentations). GPU töötleb pilte väikeste hulkadena (batch).

Näide tulemust kui, andmestiku täiendada fastai (vasakul) ja traditsioonilisel meetodil (paremal).
#caption A comparison of fastai's data augmentation strategy (left) and the traditional approach (right).
dblock1 = DataBlock(blocks=(ImageBlock(), CategoryBlock()),
get_y=parent_label,
item_tfms=Resize(460))
# Place an image in the 'images/grizzly.jpg' subfolder where this notebook is located before running this
dls1 = dblock1.dataloaders([fname]*100, bs=8) #fname = pildi faili nimi
dls1.train.get_idxs = lambda: Inf.ones
x,y = dls1.valid.one_batch()
_,axs = subplots(1, 2)
x1 = TensorImage(x.clone())
x1 = x1.affine_coord(sz=224)
x1 = x1.rotate(draw=30, p=1.)
x1 = x1.zoom(draw=1.2, p=1.)
x1 = x1.warp(draw_x=-0.2, draw_y=0.2, p=1.)
tfms = setup_aug_tfms([Rotate(draw=30, p=1, size=224), Zoom(draw=1.2, p=1., size=224),
Warp(draw_x=-0.2, draw_y=0.2, p=1., size=224)])
x = Pipeline(tfms)(x)
#x.affine_coord(coord_tfm=coord_tfm, sz=size, mode=mode, pad_mode=pad_mode)
TensorImage(x[0]).show(ctx=axs[0])
TensorImage(x1[0]).show(ctx=axs[1]);
DataBlock‘i kontrollimine
Et olla kindel et andmestik on õieti märgistatud (label).
dls.show_batch(nrows=1, ncols=3)
summary meetod kuvab palju informatsiooni. Ja annab teada, kui oleme teinud mingi vea: näiteks unustanud teha pildid ühe suuruseks (Resize).
pets1 = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'))
pets1.summary(path/"images")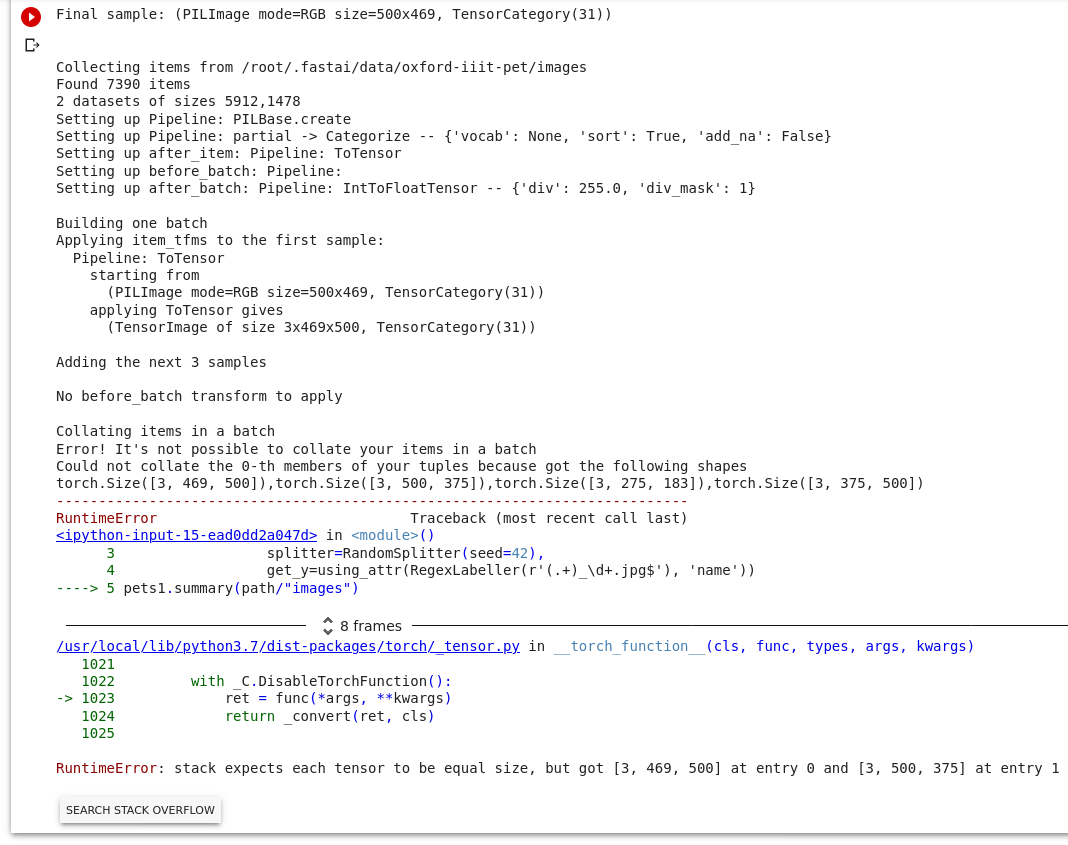
Kui tundub, et kõik on hästi. Teeme katsetamiseks esialgu lihtsa mudeli, et näha kas kõik töötab. Kui treenimi võtab hästi kaua aega siis pole käitusaja tüüp GPU peal.
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2) # 2 epohhi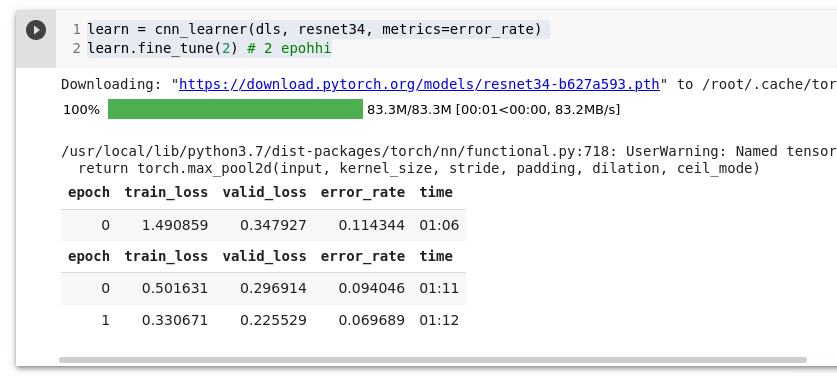
Cross-Entropy Loss
Aktiveerimine ja märgistus
one_batchkuvad ühe ühiku tegelike andmeid DataLoader’i partiist (mini-batch). Tagastab sõltumatud (independent) ja sõltuvad (dependent) muutujad. Vastavalt x ja y.
x,y = dls.one_batch()
y # dependent variable
Partii (batch) suurus on 64: tensoris on 64 rida. Iga rida on number 0 ja 36 vahel. Numbrid tähistavad tõugu. Siin andmestikus on 37 tõugu.
Learner.get_preds – tagastab ennustused (predictions) ja eesmärgid (targets).
preds,_ = learn.get_preds(dl=[(x,y)])
preds[0]
len(preds[0]),preds[0].sum()Softmax
Kasutame softmax aktiveerimisfunktsiooni viimasel kihil, et olla kindel aktiveerimine on 0 ja 1 vahel. Ja summa oleks kokku 1.
Softmax on sarnane sigmoidfunktsiooniga.
Kasutame sigmoidi siis, kui meil on ainult kaks kategooriat: näiteks kass või koer. Kui on rohkem, kui 2 kategooriat kasutame softmaxi.
Kuvame sigmoidi:
plot_function(torch.sigmoid, min=-4,max=4)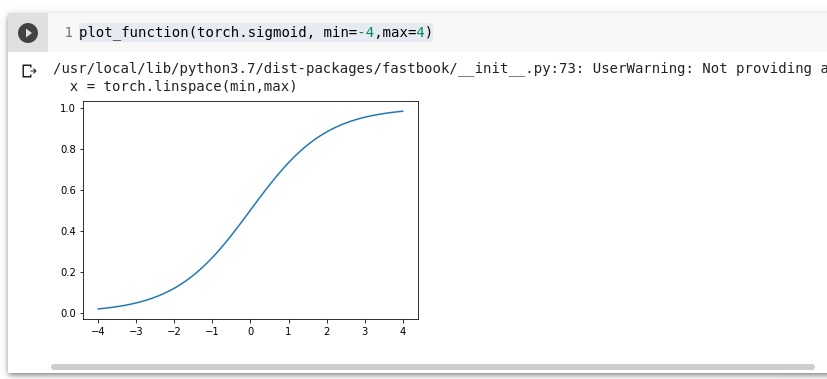
Log tõenäosus (Log Likelihood)
plot_function(torch.log, min=0,max=4)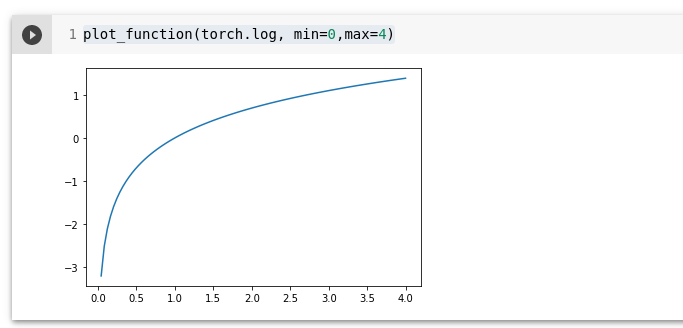
Kui esmalt võtame softmax ja siis log likelihood sellest siis seda kobinatsiooni nimetatakse cross-entropy loss.
Mudeli tõlgendamine (interpretation)
Kuvame kogu andmestiku kohta confusion matrixi:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)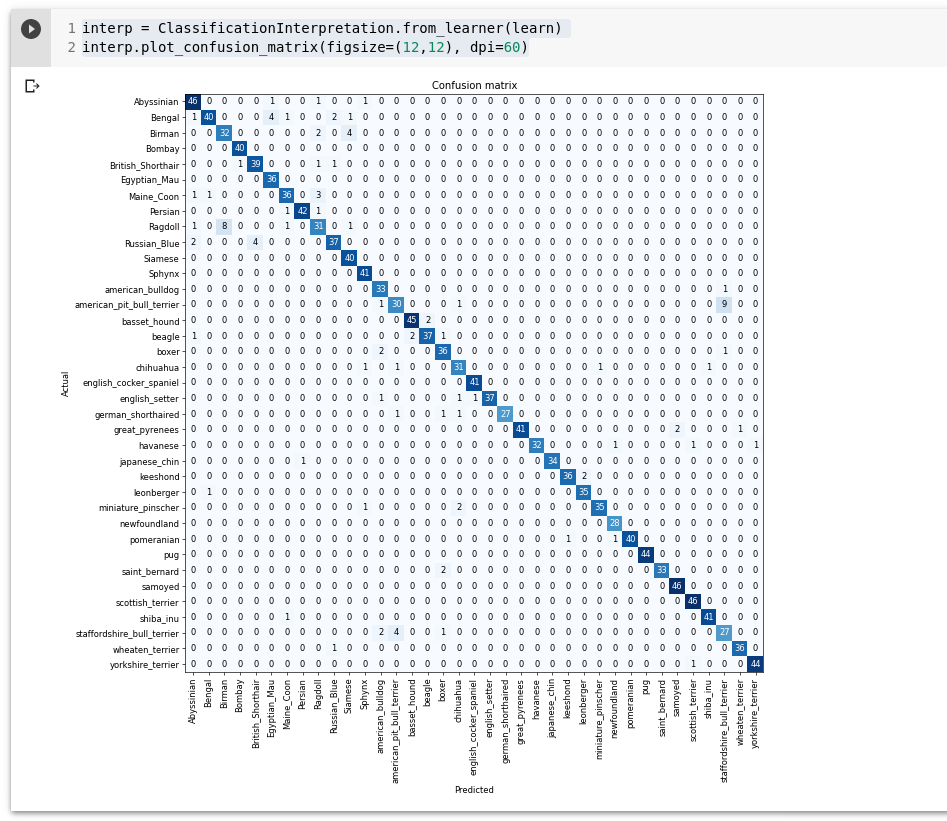
Et näha ainult neid millega kõige rohkem probleeme on:
interp.most_confused(min_val=5)
Mudeli täiustamine
transfer learning – siirdeõpe, ülekandeõpe
Õpisamm (Learning Rate)
On oluline leida õige õpisamm. Kui on liiga lühike (low) on vaja palju epohhe mudeli treenimiseks. See raiskab aega ja võib toimuda ülesobitumine.
Proovime pikka (high) sammuga treenida:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1, base_lr=0.1)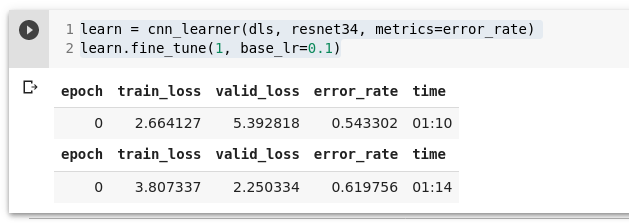
Ei tundu hea. Optimeerija sammus õiges suunas aga astus üle minimaalse kao (loss) punktist.
Kuidas leida õiget õpisammu?
learning rate finder
learn = cnn_learner(dls, resnet34, metrics=error_rate)
suggestion = learn.lr_find() # tundub see f on muutunud võrreldes raamatuga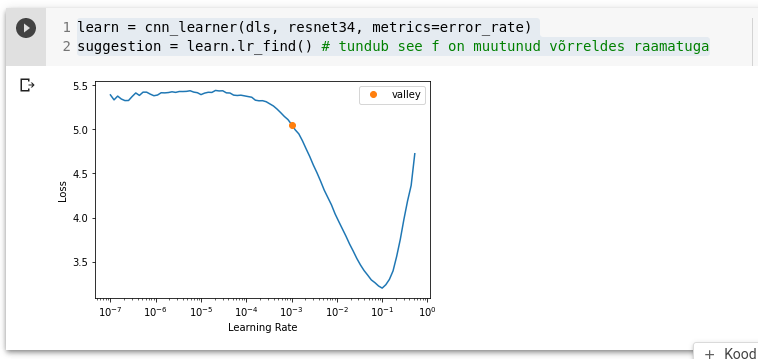
suggestion
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2, base_lr=0.0010) # raamat soovitab 3e-3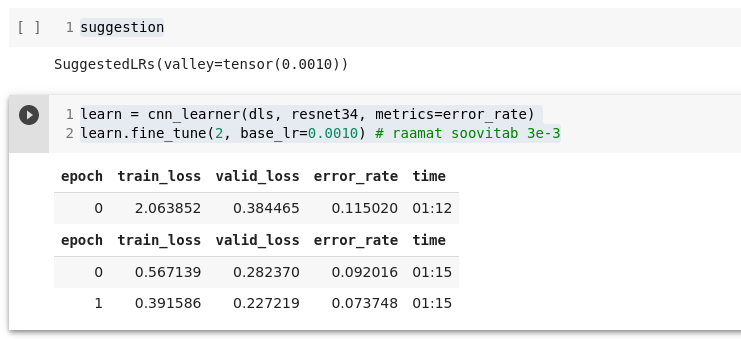
Ülekandeõpe (Transfer Learning)
Konvolutsioonilised närvivõrgud koosnevad paljudest lineaarsetest kihtidest mille vahel on mittelineaarsed aktiveerimis funktsioonid. Lõppus on ka lineaarne ja aktiveerimis funktsioon nagu softmax.
Eeltreenitud mudelite puhul eemaldame viimase, mis sisaldab kategooriaid milleks see mudel algselt oli treenitud. Ja asendame uuega, kus on õige arv väljundeid. Eelnevad kihid on juba treenitud äratundma üldiseid piltide osi. Viimane kiht tegeleb konkreetselt meie spetsiifilise ülesandega.
Sellel uuel kihil on juhuslikud parameetrid/kaalud (weights). Ja esmalt me treenime ainult seda kihti ühe korra st. muudame selle kihi kaale. Kõikide teiste kihtide kaalud ei muutu. Ja seejärel treenime kogu mudelit.
Katsetame seda manuaalselt:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 0.0010) # viimane kiht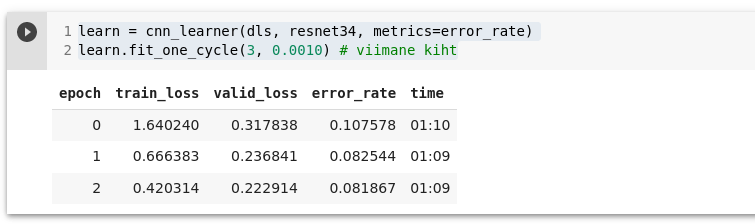
Leiame uue õpisamu
learn.unfreeze()
sug = learn.lr_find()
sug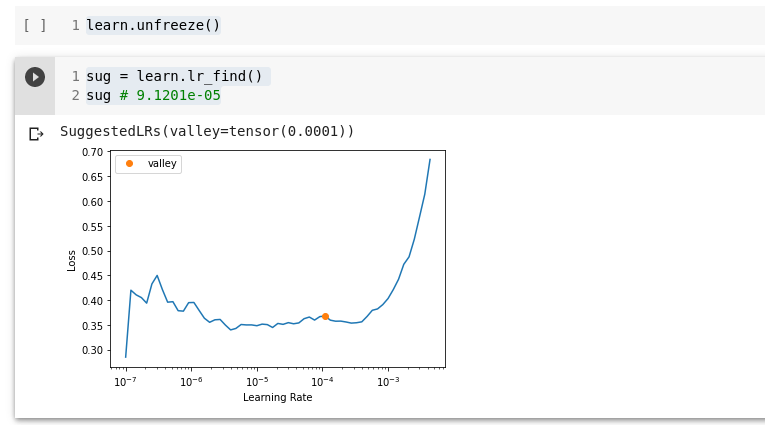
Treenime uuesti:
learn.fit_one_cycle(6, lr_max=0.0001)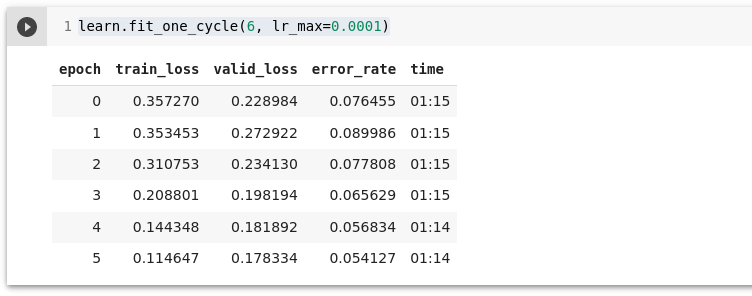
Diskrimineerivad õpisammud
Discriminative Learning Rates
Esimesed kihid (layers) mudelis lihtsaid asju nagu serva äratundmine, heleduse/tumeduse üleminekud, jooned jne. Tagumised kihid õpivad juba konkreetsemaid asju ära tundma nagu silm, päikseloojang jne. Seega vajadus ümberõppida on suurem viimastel kihtidel. Esimestel kihtidel peaks õpisamm (learning rate) olema väiksem (lower) ja suurem (higher) viimastel kihtidel.
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 0.0010)
learn.unfreeze()
learn.fit_one_cycle(12, lr_max=slice(1e-5,1e-3))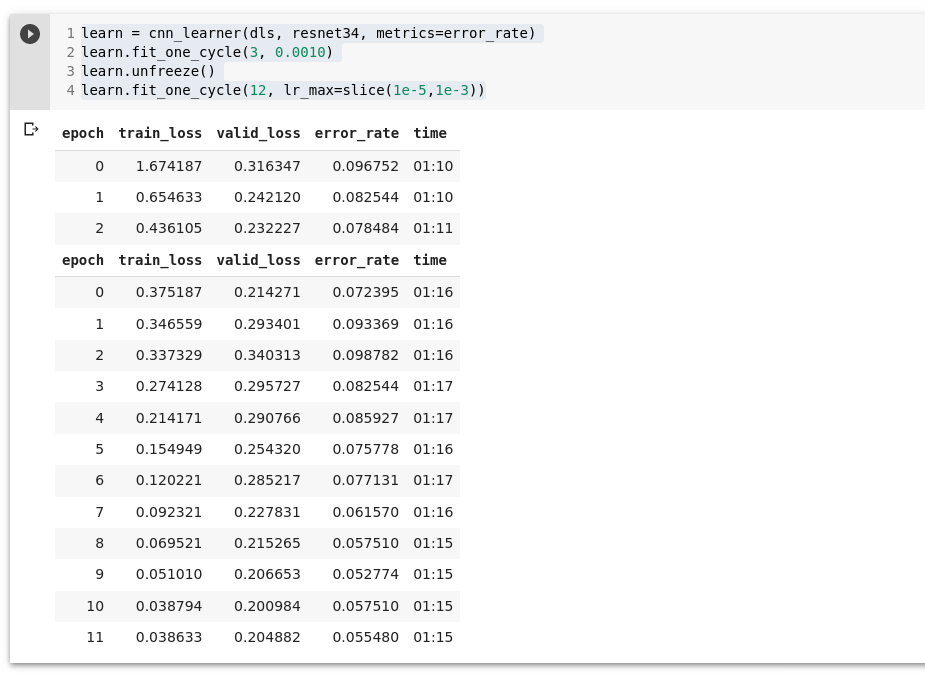
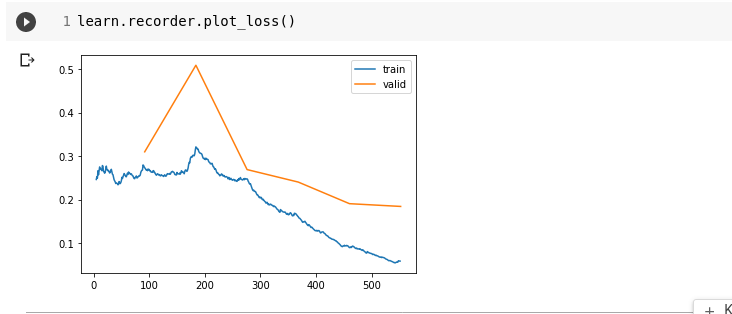
Kuvame graaviku treening ja valideerimiskaost (loss).
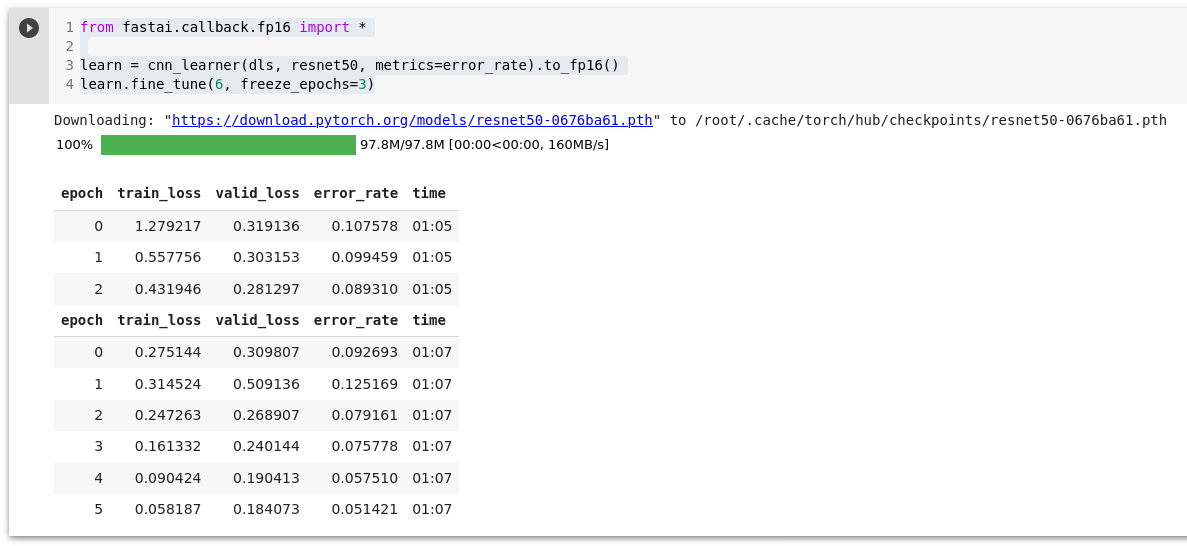
learn.recorder.plot_loss()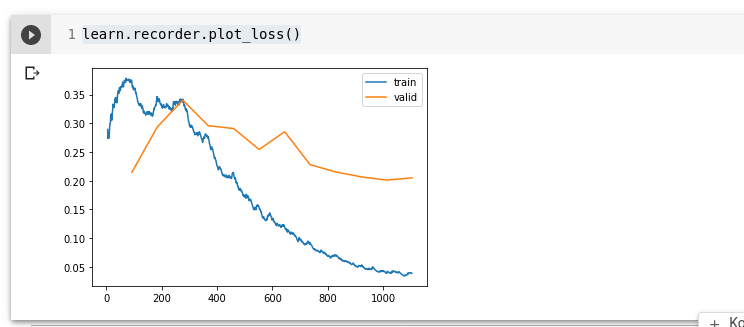
Punkt, kust valideerimis andmed hakkavad halvenemea aga treening andmed paranevad on koht, kus toimub ülesobitumine (over fit).
mixed-precision training – võimaluse korral vähem täpsete arvude kasutamine (Pooltäpsed ujukomaarvud – fp16) treeningu ajal. Peaaegu kõigil uutel NVIDA GPUdel on spetsiaalne tensor cores, mis võimaldab treenimisaega kiirendada 2-3 korda.
from fastai.callback.fp16 import *
learn = cnn_learner(dls, resnet50, metrics=error_rate).to_fp16()
learn.fine_tune(6, freeze_epochs=3)